我有一些文件,需要按照每行开头的ID进行排序。这些文件大约有2-3GB。
我尝试将所有数据读入ArrayList并进行排序。但是内存不足以容纳它们。它无法工作。
每行看起来像
0052304 0000004000000000000000000000000000000041 约翰·泰迪 000023
0022024 0000004000000000000000000000000000000041 乔治·克兰 00013
如何对文件进行排序?
我有一些文件,需要按照每行开头的ID进行排序。这些文件大约有2-3GB。
我尝试将所有数据读入ArrayList并进行排序。但是内存不足以容纳它们。它无法工作。
每行看起来像
0052304 0000004000000000000000000000000000000041 约翰·泰迪 000023
0022024 0000004000000000000000000000000000000041 乔治·克兰 00013
如何对文件进行排序?
由于您的记录已经以平面文件文本格式存在,因此您可以将它们输入UNIX sort(1)(例如sort -n -t' ' -k1,1 < input > output)进行排序。它会自动对数据进行分块并使用可用内存和/tmp执行合并排序。如果需要比您可用内存更多的空间,请在命令中添加-T /tmpdir。
有趣的是,每个人都告诉您下载巨大的C#或Java库或自己实现合并排序,而您可以使用适用于每个平台并存在数十年的工具。
sort可执行文件。 - jimpudar您需要使用外部合并排序来完成此操作。 这里 提供了一个Java实现,可以对非常大的文件进行排序。
不要一次性将所有数据加载到内存中,您可以只读取键和行的起始位置的索引(可能还包括长度)例如:
class Line {
int key, length;
long start;
}
每行大约会使用40个字节。
一旦您对该数组进行了排序,就可以使用RandomAccessFile按它们出现的顺序读取这些行。
注意:由于您将随机访问磁盘而不是使用内存,因此这可能非常慢。典型的磁盘需要8毫秒才能随机访问数据,如果您有1000万行,则需要大约一天的时间。(这是绝对最坏的情况)在内存中,这将花费大约10秒钟。
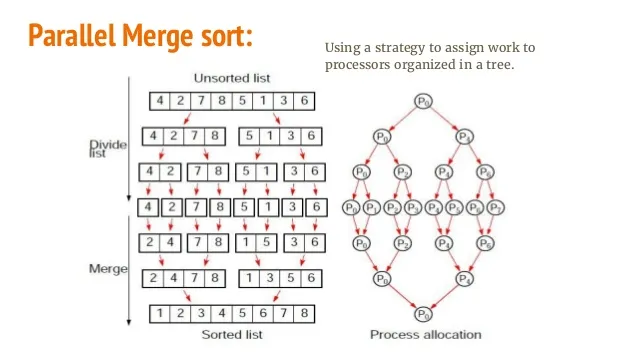 更改这些行以符合您的系统。
更改这些行以符合您的系统。 fpath 是您的一个大输入文件(已测试20GB)。 shared 路径是存储执行日志的位置。 fdir 是中间文件将被存储和合并的位置。根据您的机器更改这些路径。public static final String fdir = "/tmp/";
public static final String shared = "/exports/home/schatterjee/cs553-pa2a/";
public static final String fPath = "/input/data-20GB.in";
public static final String opLog = shared+"Mysort20GB.log";
fdir中。最后一行Runtime.getRuntime().exec("valsort " + fdir + "op" + (treeHeight*100)+1 + " > " + opLog);检查输出是否已排序。如果您没有安装valsort或输入文件不是使用gensort生成的(http://www.ordinal.com/gensort.html),请删除此行。int totalLines = 200000000;更改为文件中的总行数。线程计数(int threadCount = 16)应始终为2的幂,并且足够大,以便(总大小*2 / 线程数)的数据可以驻留在内存中。更改线程计数将更改最终输出文件的名称。例如对于16,它将是op401,对于32,它将是op501,对于8,它将是op301等。 import java.io.*;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.stream.Stream;
class SplitFile extends Thread {
String fileName;
int startLine, endLine;
SplitFile(String fileName, int startLine, int endLine) {
this.fileName = fileName;
this.startLine = startLine;
this.endLine = endLine;
}
public static void writeToFile(BufferedWriter writer, String line) {
try {
writer.write(line + "\r\n");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public void run() {
try {
BufferedWriter writer = Files.newBufferedWriter(Paths.get(fileName));
int totalLines = endLine + 1 - startLine;
Stream<String> chunks =
Files.lines(Paths.get(Mysort20GB.fPath))
.skip(startLine - 1)
.limit(totalLines)
.sorted(Comparator.naturalOrder());
chunks.forEach(line -> {
writeToFile(writer, line);
});
System.out.println(" Done Writing " + Thread.currentThread().getName());
writer.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
class MergeFiles extends Thread {
String file1, file2, file3;
MergeFiles(String file1, String file2, String file3) {
this.file1 = file1;
this.file2 = file2;
this.file3 = file3;
}
public void run() {
try {
System.out.println(file1 + " Started Merging " + file2 );
FileReader fileReader1 = new FileReader(file1);
FileReader fileReader2 = new FileReader(file2);
FileWriter writer = new FileWriter(file3);
BufferedReader bufferedReader1 = new BufferedReader(fileReader1);
BufferedReader bufferedReader2 = new BufferedReader(fileReader2);
String line1 = bufferedReader1.readLine();
String line2 = bufferedReader2.readLine();
//Merge 2 files based on which string is greater.
while (line1 != null || line2 != null) {
if (line1 == null || (line2 != null && line1.compareTo(line2) > 0)) {
writer.write(line2 + "\r\n");
line2 = bufferedReader2.readLine();
} else {
writer.write(line1 + "\r\n");
line1 = bufferedReader1.readLine();
}
}
System.out.println(file1 + " Done Merging " + file2 );
new File(file1).delete();
new File(file2).delete();
writer.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
public class Mysort20GB {
//public static final String fdir = "/Users/diesel/Desktop/";
public static final String fdir = "/tmp/";
public static final String shared = "/exports/home/schatterjee/cs553-pa2a/";
public static final String fPath = "/input/data-20GB.in";
public static final String opLog = shared+"Mysort20GB.log";
public static void main(String[] args) throws Exception{
long startTime = System.nanoTime();
int threadCount = 16; // Number of threads
int totalLines = 200000000;
int linesPerFile = totalLines / threadCount;
ArrayList<Thread> activeThreads = new ArrayList<Thread>();
for (int i = 1; i <= threadCount; i++) {
int startLine = i == 1 ? i : (i - 1) * linesPerFile + 1;
int endLine = i * linesPerFile;
SplitFile mapThreads = new SplitFile(fdir + "op" + i, startLine, endLine);
activeThreads.add(mapThreads);
mapThreads.start();
}
activeThreads.stream().forEach(t -> {
try {
t.join();
} catch (Exception e) {
}
});
int treeHeight = (int) (Math.log(threadCount) / Math.log(2));
for (int i = 0; i < treeHeight; i++) {
ArrayList<Thread> actvThreads = new ArrayList<Thread>();
for (int j = 1, itr = 1; j <= threadCount / (i + 1); j += 2, itr++) {
int offset = i * 100;
String tempFile1 = fdir + "op" + (j + offset);
String tempFile2 = fdir + "op" + ((j + 1) + offset);
String opFile = fdir + "op" + (itr + ((i + 1) * 100));
MergeFiles reduceThreads =
new MergeFiles(tempFile1,tempFile2,opFile);
actvThreads.add(reduceThreads);
reduceThreads.start();
}
actvThreads.stream().forEach(t -> {
try {
t.join();
} catch (Exception e) {
}
});
}
long endTime = System.nanoTime();
double timeTaken = (endTime - startTime)/1e9;
System.out.println(timeTaken);
BufferedWriter logFile = new BufferedWriter(new FileWriter(opLog, true));
logFile.write("Time Taken in seconds:" + timeTaken);
Runtime.getRuntime().exec("valsort " + fdir + "op" + (treeHeight*100)+1 + " > " + opLog);
logFile.close();
}
}
使用Java库big-sorter可对非常大的文本或二进制文件进行排序。
以下是实现您确切问题的方法:
// write the input to a file
String s = "0052304 0000004000000000000000000000000000000041 John Teddy 000023\n"
+ "0022024 0000004000000000000000000000000000000041 George Clan 00013";
File input = new File("target/input");
Files.write(input.toPath(),s.getBytes(StandardCharsets.UTF_8), StandardOpenOption.WRITE);
File output = new File("target/output");
//sort the input
Sorter
.serializerLinesUtf8()
.comparator((a,b) -> {
String ida = a.substring(0, a.indexOf(' '));
String idb = b.substring(0, b.indexOf(' '));
return ida.compareTo(idb);
})
.input(input)
.output(output)
.sort();
// display the output
Files.readAllLines(output.toPath()).forEach(System.out::println);
输出:
0022024 0000004000000000000000000000000000000041 George Clan 00013
0052304 0000004000000000000000000000000000000041 John Teddy 000023
https://sites.google.com/site/arjunwebworld/Home/programming/sorting-large-data-files
我使用了自己的逻辑,将一个大的JSON文件按照格式排序。
{"name":"hoge.finance","address":"0xfAd45E47083e4607302aa43c65fB3106F1cd7607"}
// at this point, we have sorted data sets in respective files
// next, we will take first token from first file and compare it with tokens of all other files
// during comparison, if some token from other file is in sorted order, then we make it default/initial sorted token
// & jump to next file, since all remaining tokens in THAT file are already in sorted form
// at end of comparisons with all files, we remove it from specific file (so it's not compared next time) and put/append in final sorted file
// this process continues, until all entries are matched
// if some file has no entries, then we simply delete it (so it's not compared next time)
public static void runScript(final Logger log, final String scriptFile) throws IOException, InterruptedException {
final String command = scriptFile;
if (!new File (command).exists() || !new File(command).canRead() || !new File(command).canExecute()) {
log.log(Level.SEVERE, "Cannot find or read " + command);
log.log(Level.WARNING, "Make sure the file is executable and you have permissions to execute it. Hint: use \"chmod +x filename\" to make it executable");
throw new IOException("Cannot find or read " + command);
}
final int returncode = Runtime.getRuntime().exec(new String[] {"bash", "-c", command}).waitFor();
if (returncode!=0) {
log.log(Level.SEVERE, "The script returned an Error with exit code: " + returncode);
throw new IOException();
}
}