有没有一种方法可以提取kmeans聚类中节点和质心之间的距离。
我对文本嵌入数据集进行了Kmeans聚类,想知道每个簇中与质心相距较远的节点是哪些,以便检查相应节点的特征,看它们有何不同。
提前感谢!
有没有一种方法可以提取kmeans聚类中节点和质心之间的距离。
我对文本嵌入数据集进行了Kmeans聚类,想知道每个簇中与质心相距较远的节点是哪些,以便检查相应节点的特征,看它们有何不同。
提前感谢!
KMeans.transform() 返回每个样本到聚类中心的距离数组。
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import seaborn as sns
# Generate some random clusters
X, y = make_blobs()
kmeans = KMeans(n_clusters=3).fit(X)
# plot the cluster centers and samples
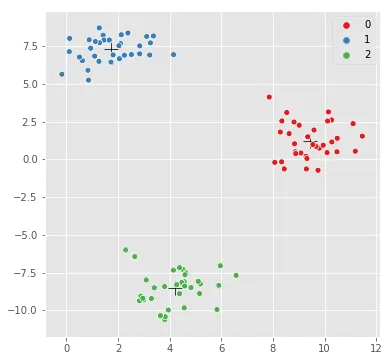
sns.scatterplot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1],
marker='+',
color='black',
s=200);
sns.scatterplot(X[:,0], X[:,1], hue=y,
palette=sns.color_palette("Set1", n_colors=3));
transform X并取每行的和(axis=1)来确定距离中心最远的样本。
# squared distance to cluster center
X_dist = kmeans.transform(X)**2
# do something useful...
import pandas as pd
df = pd.DataFrame(X_dist.sum(axis=1).round(2), columns=['sqdist'])
df['label'] = y
df.head()
sqdist label
0 211.12 0
1 257.58 0
2 347.08 1
3 209.69 0
4 244.54 0
一个可视化检查--相同的图形,只是这次突出显示每个聚类中心最远的点:
# for each cluster, find the furthest point
max_indices = []
for label in np.unique(kmeans.labels_):
X_label_indices = np.where(y==label)[0]
max_label_idx = X_label_indices[np.argmax(X_dist[y==label].sum(axis=1))]
max_indices.append(max_label_idx)
# replot, but highlight the furthest point
sns.scatterplot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1],
marker='+',
color='black',
s=200);
sns.scatterplot(X[:,0], X[:,1], hue=y,
palette=sns.color_palette("Set1", n_colors=3));
# highlight the furthest point in black
sns.scatterplot(X[max_indices, 0], X[max_indices, 1], color='black');
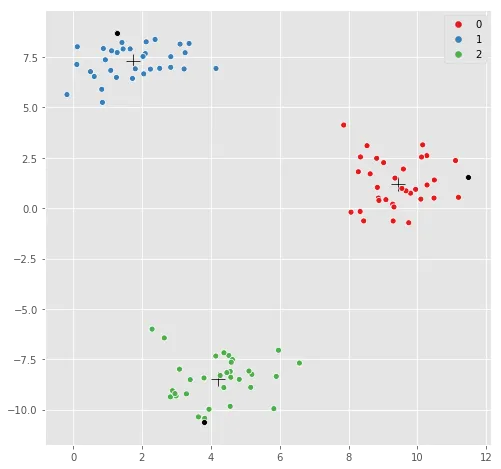
labels_和cluster_centers_。labels_进行过滤,并为每个标签内的每个点计算距离。Kevin的回答很好,但我觉得它没有回答所提出的问题(也许我完全读错了)。如果您想查看每个单独的聚类中心并获取该聚类中距离中心最远的点,则需要使用聚类标签来获取每个点到该聚类质心的距离。上面的代码只是找到每个聚类中距离所有其他聚类中心最远的点(您可以在图片中看到,这些点总是在聚类的另外两个聚类的远侧)。为了查看单个聚类,您需要像以下内容:
center_dists = np.array([X_dist[i][x] for i,x in enumerate(y)])
这将为您提供每个点到其簇质心的距离。然后通过运行与Kevin上面几乎相同的代码,它将为您提供每个簇中最远的点。
max_indices = []
for label in np.unique(kmeans.labels_):
X_label_indices = np.where(y==label)[0]
max_label_idx = X_label_indices[np.argmax(center_dists[y==label])]
max_indices.append(max_label_idx)