我有一个大小为
以下是一个代码片段,显示了我的当前方法,其中对
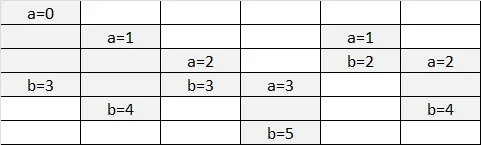
例如(当
m*m的二维数组,元素值为0或1。此外,该数组的每一列都有一个连续的1块(其余为0)。该数组本身太大,无法存储在内存中(多达10^6行),但对于每一列,我可以确定该列中1的下限a和上限b。对于给定的n,我需要找出具有最大数量1的n个连续行。我可以通过逐行计算总和并选择总和最大的n个连续行来轻松完成较小数字的操作,但对于大数字,它将消耗过多时间。是否有任何有效的方法来计算这个问题?也许使用动态规划?以下是一个代码片段,显示了我的当前方法,其中对
read_int()的连续调用(未在此处给出)提供了连续列的下限和上限: long int harr[10000]={0}; //initialized to zero
for(int i=0;i<m;i++)
{
a=read_int();
b=read_int();
for(int j=a;j<=b;j++) // for finding sum of each row
harr[j]++;
}
answer=0;
for(int i=0;i<n;i++)
{
answer=answer+harr[i];
}
current=answer;
for(int i=n;i<m;i++)
{
current=current+harr[i]-harr[i-n];
if(current>answer)
{
answer=current;
}
}
例如(当
m = 6且n = 3时)
n是一个输入参数,满足n <= m? - John Colemani列中哪些行具有最大数量的1,当你从0迭代到结尾时,你会发现一些行没有希望赶上当前的最大值。最坏情况(所有地方都是1或0)不会改善。最好的情况下你可以把时间减半。 - user3528438harr中确定answer的方式存在任何低效性。这在行数上是线性的,即使有100万行(而不是您代码示例中的10000行),该计算部分也将在几秒钟内运行。我怀疑在加载harr时不断更新临时的answer是否会产生反作用。您确定read_int()不是瓶颈吗? - John Coleman