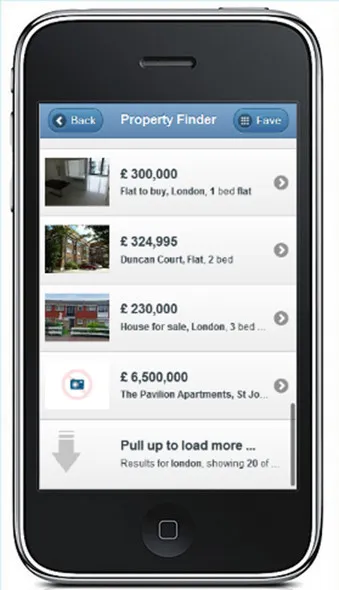
根据您的服务器端逻辑,可能有两种方法。
方法一:当服务器不能够处理对象状态时
您可以将所有缓存记录唯一标识符发送到服务器,例如["id1","id2","id3","id4","id5","id6","id7","id8","id9","id10"]和一个布尔参数,以了解您是否正在请求新记录(下拉刷新)或旧记录(加载更多)。
您的服务器应负责返回新记录(通过加载更多记录或下拉刷新)以及从 ["id1","id2","id3","id4","id5","id6","id7","id8","id9","id10"] 中删除的记录的 ID。
示例:
如果您正在请求“加载更多”,则您的请求应如下所示:
{
"isRefresh" : false,
"cached" : ["id1","id2","id3","id4","id5","id6","id7","id8","id9","id10"]
}
现在假设您正在请求旧记录(加载更多),并且假设“id2”记录已被某人更新,而服务器上的“id5”和“id8”记录已被删除,则您的服务器响应应该看起来像这样:
{
"records" : [
{"id" :"id2","more_key":"updated_value"},
{"id" :"id11","more_key":"more_value"},
{"id" :"id12","more_key":"more_value"},
{"id" :"id13","more_key":"more_value"},
{"id" :"id14","more_key":"more_value"},
{"id" :"id15","more_key":"more_value"},
{"id" :"id16","more_key":"more_value"},
{"id" :"id17","more_key":"more_value"},
{"id" :"id18","more_key":"more_value"},
{"id" :"id19","more_key":"more_value"},
{"id" :"id20","more_key":"more_value"}],
"deleted" : ["id5","id8"]
}
但是在这种情况下,如果你有很多本地缓存记录,假设有500条,那么你的请求字符串会变得过长,就像这样:
但是在这种情况下,如果您有大量本地缓存记录(比如500条),则您的请求字符串将变得过长,类似于:
{
"isRefresh" : false,
"cached" : ["id1","id2","id3","id4","id5","id6","id7","id8","id9","id10",………,"id500"]
}
方法2:当服务器足够智能,能够根据日期处理对象状态。
您可以发送第一个记录和最后一个记录的ID以及上一个请求的时间戳。这样,即使您有大量缓存记录,您的请求也始终很小。
例如:
如果您正在请求加载更多内容,则请求应该类似于以下内容:
{
"isRefresh" : false,
"firstId" : "id1",
"lastId" : "id10",
"last_request_time" : 1421748005
}
您的服务器需要负责返回在最后一次请求时间之后被删除的记录的ID,以及在“id1”和“id10”之间的最后一次请求时间之后更新的记录。
您的服务器需要负责返回在最后一次请求时间之后被删除的记录的ID,以及在“id1”和“id10”之间的最后一次请求时间之后更新的记录。
{
"records" : [
{"id" :"id2","more_key":"updated_value"},
{"id" :"id11","more_key":"more_value"},
{"id" :"id12","more_key":"more_value"},
{"id" :"id13","more_key":"more_value"},
{"id" :"id14","more_key":"more_value"},
{"id" :"id15","more_key":"more_value"},
{"id" :"id16","more_key":"more_value"},
{"id" :"id17","more_key":"more_value"},
{"id" :"id18","more_key":"more_value"},
{"id" :"id19","more_key":"more_value"},
{"id" :"id20","more_key":"more_value"}],
"deleted" : ["id5","id8"]
}
下拉刷新:
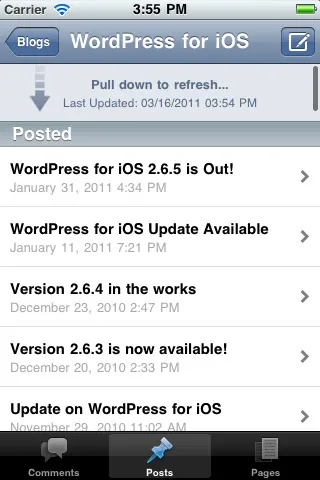
加载更多