我有一个项目,利用Google Vision API DOCUMENT_TEXT_DETECTION从文档图像中提取文本。
通常API在识别单个数字时会遇到困难,如下图所示:
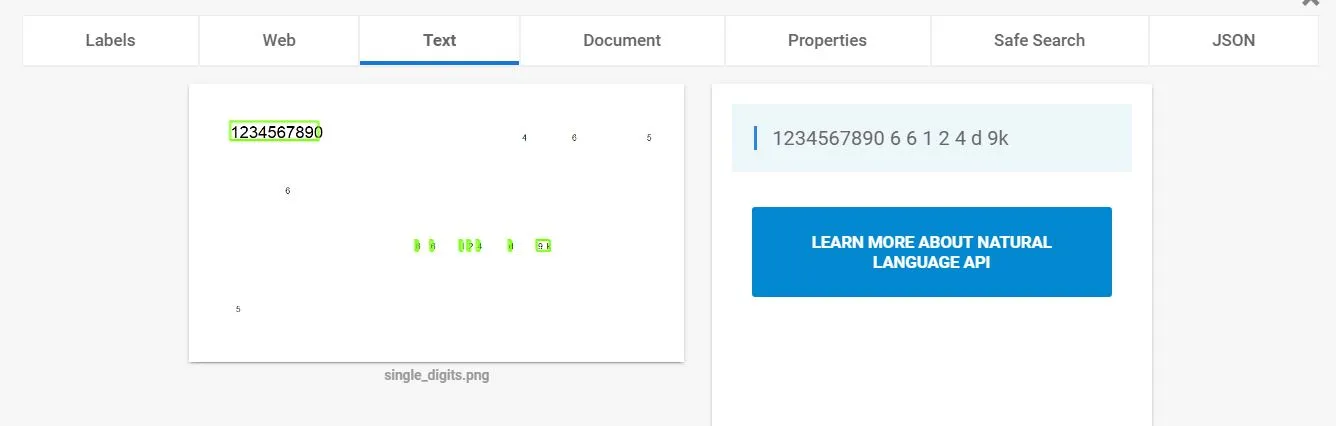
我认为问题可能与去噪算法有关,它将孤立的单个数字识别为噪声。是否有一种方法可以改进这些情况下的Vision响应?(例如管理噪声阈值或其他参数)
其他情况下,Vision会混淆数字和字母:
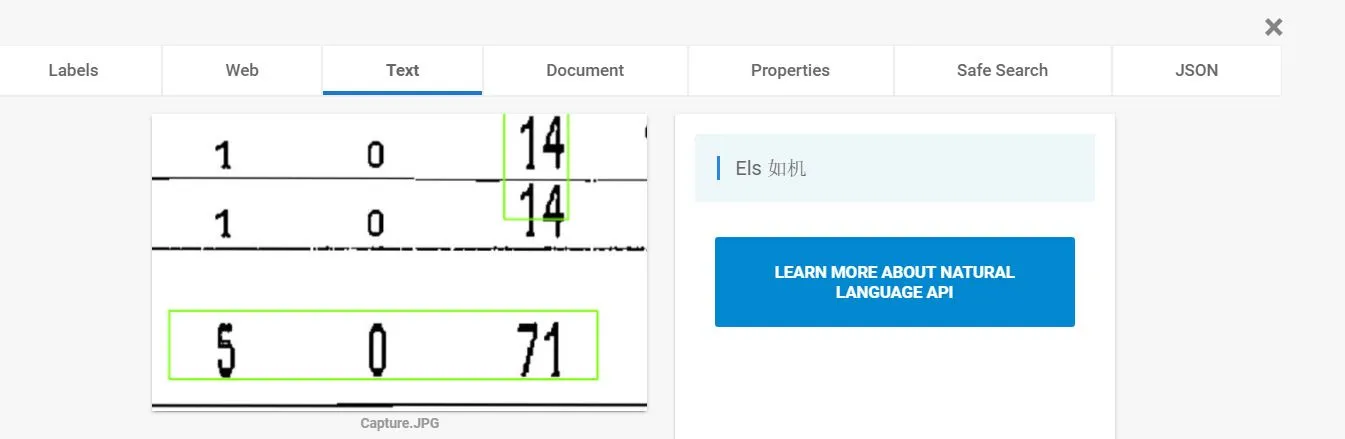
但如果我将languageHints参数指定为'en'或'mt',OCR将忽略这些数字。是否有一种方法可以强制识别数字或拉丁字符?
我有一个项目,利用Google Vision API DOCUMENT_TEXT_DETECTION从文档图像中提取文本。
通常API在识别单个数字时会遇到困难,如下图所示:
我认为问题可能与去噪算法有关,它将孤立的单个数字识别为噪声。是否有一种方法可以改进这些情况下的Vision响应?(例如管理噪声阈值或其他参数)
其他情况下,Vision会混淆数字和字母:
但如果我将languageHints参数指定为'en'或'mt',OCR将忽略这些数字。是否有一种方法可以强制识别数字或拉丁字符?
DOCUMENT_TEXT_DETECTION),另一端是任意位文本(TEXT_DETECTION)。正如您在评论中指出的那样,常规的TEXT_DETECTION适用于这些散乱的单个数字,而DOCUMENT_TEXT_DETECTION则总体效果更好。
TEXT_DETECTION。如 文档 所述,DOCUMENT_TEXT_DETECTION用于优化密集的文本。但你所使用的图像似乎不是这种情况。 - enle lin