在BigQuery中,将包含两个数组的结构体展开的正确方法是什么?我有一个数据集,就像这里展示的一样(struct.destination和struct.visitors数组是有序的 - 即访问者计数与同一行中的目的地对应):
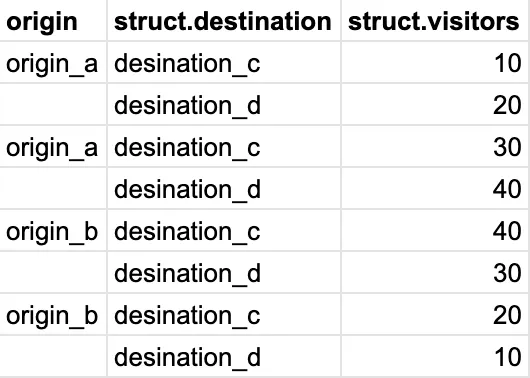
我希望重新组织数据,以便为每个唯一的起点和目的地组合获得总访问者计数。理想情况下,最终结果将如下所示:

SELECT
origin,
unnested_destination,
unnested_visitors
FROM
dataset.table,
UNNEST(struct.destination) AS unnested_destination,
UNNEST(struct.visitors) AS unnested_visitors
s WITH offset” 应该是指的是 “d WITH offset” 吗? - dlamblin