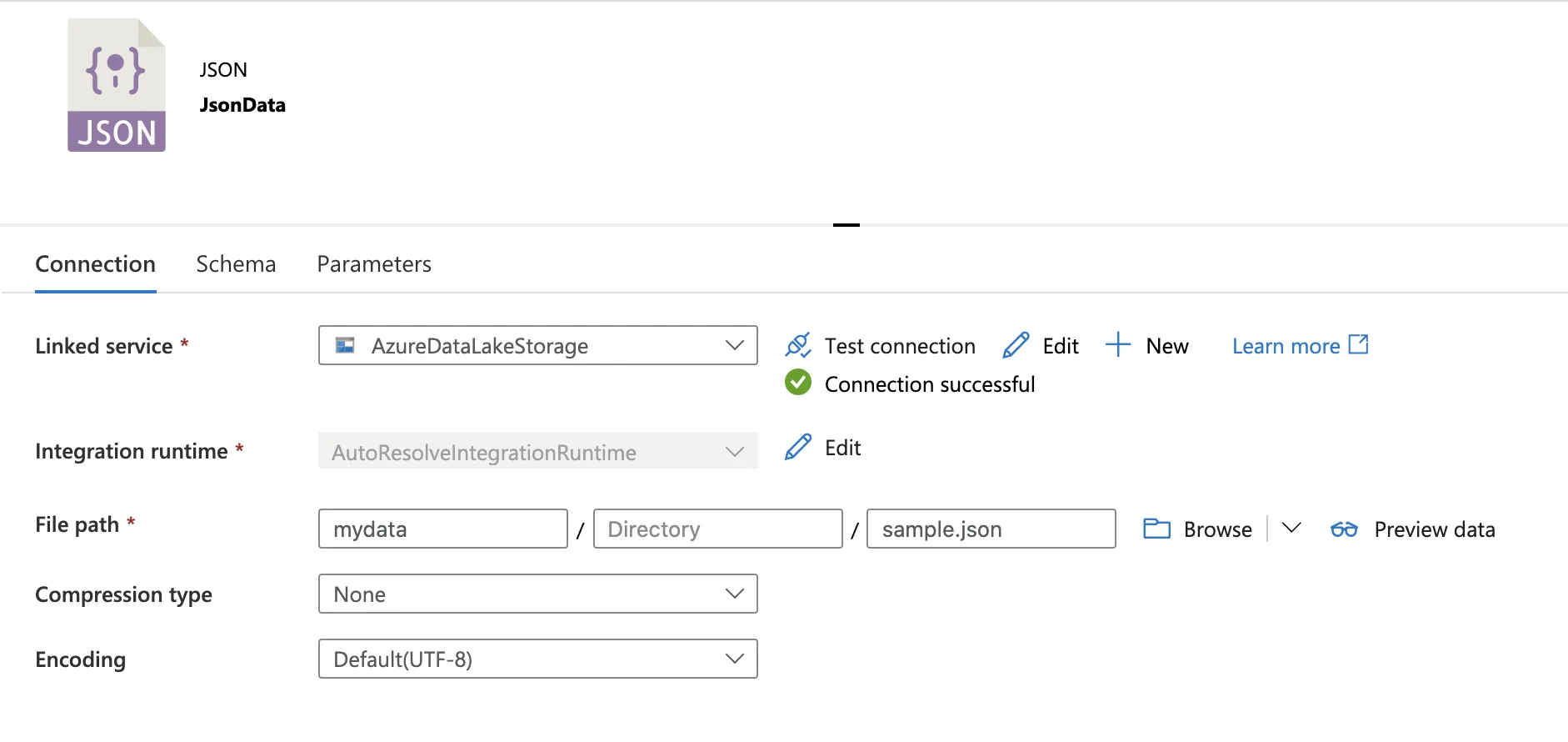
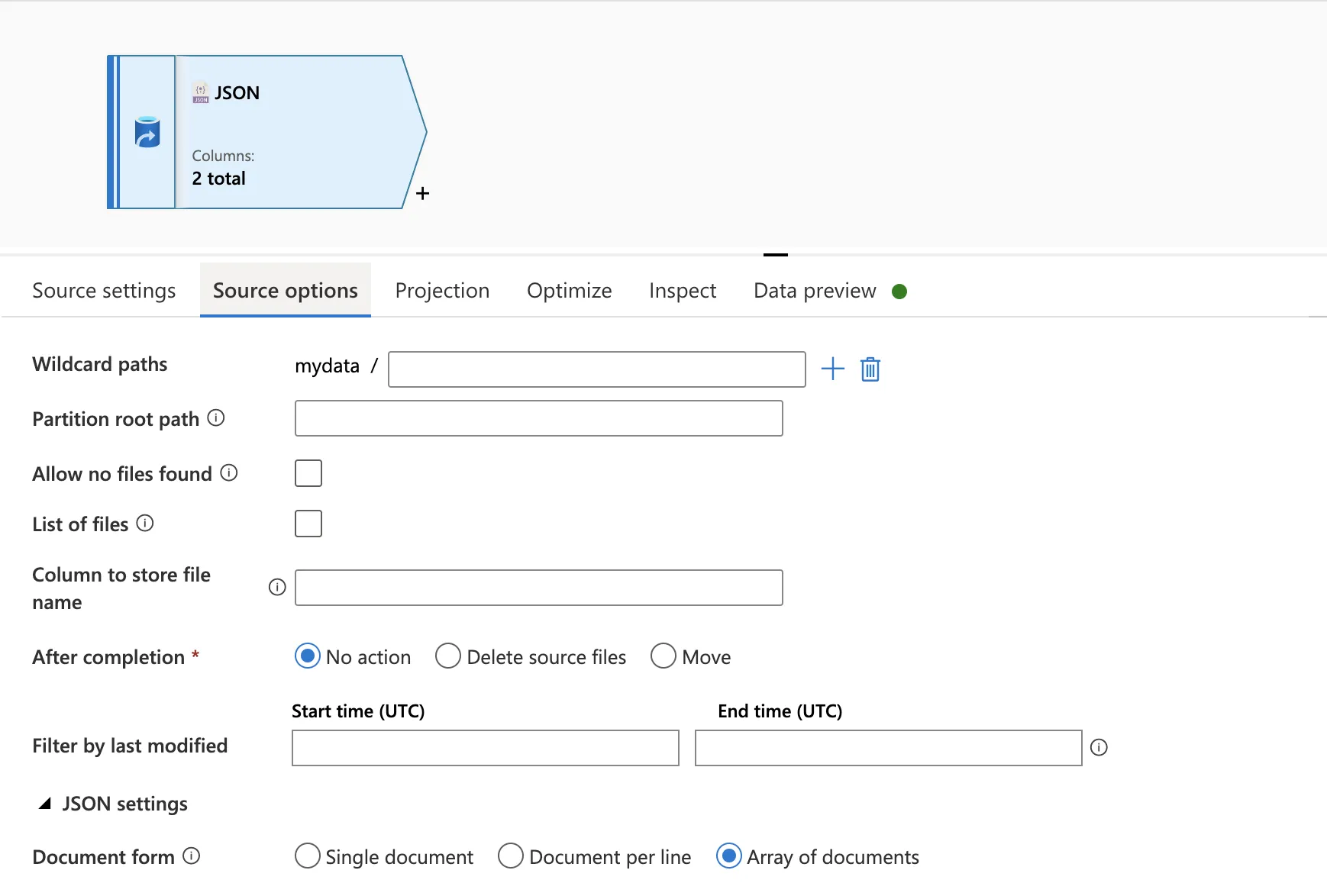
我在使用ADF中的数据集解析Blob存储中读取的基本Json时遇到了非常令人沮丧的错误。
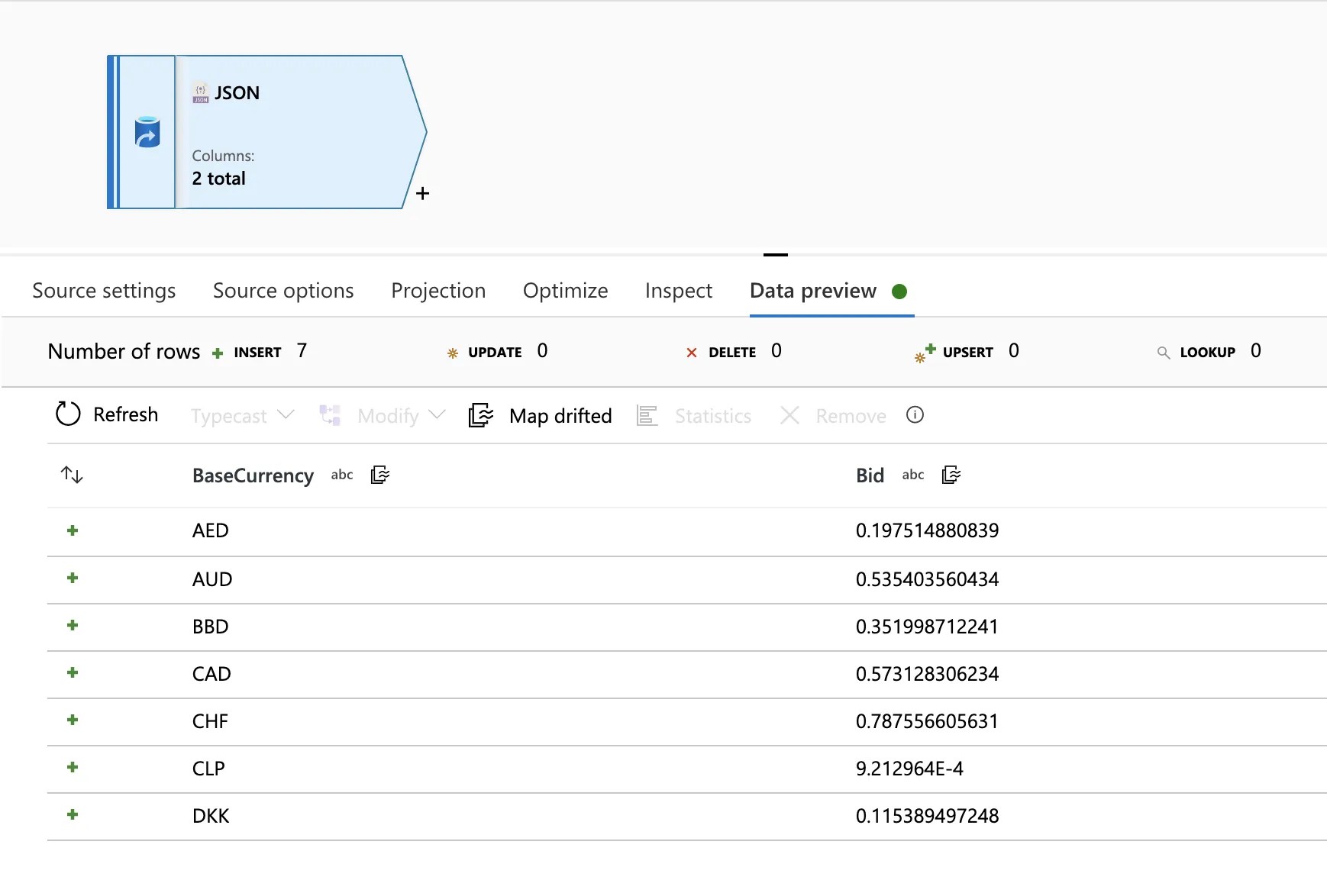
以下是我的Json:
[{"Bid":0.197514880839,"BaseCurrency":"AED"}
,{"Bid":0.535403560434,"BaseCurrency":"AUD"}
,{"Bid":0.351998712241,"BaseCurrency":"BBD"}
,{"Bid":0.573128306234,"BaseCurrency":"CAD"}
,{"Bid":0.787556605631,"BaseCurrency":"CHF"}
,{"Bid":0.0009212964,"BaseCurrency":"CLP"}
,{"Bid":0.115389497248,"BaseCurrency":"DKK"}
]
我尝试了所有三个Json源设置,但每一个都会出现错误。
Malformed records are detected in schema inference. Parse Mode: FAILFAST
这里所说的3个设置指的是:
Single Document
Array Of Documents
Document Per Line
有谁能帮忙吗?我只需要把这个东西变成对象列表就行了!
Paul