我正在尝试解决以下问题:
给定出生日期和死亡日期列表,找到最多人活着的年份。
以下是我的代码:
b = [1791, 1796, 1691, 1907, 1999, 2001, 1907] # birth dates
d = [1800, 1803, 1692, 1907, 1852, 1980, 2006] # death dates
year_dict = {} # populates dict key as year, val as total living/dead
for birth in b:
year_dict.setdefault(birth,0) # sets default value of key to 0
year_dict[birth] += 1 # will add +1 for each birth and sums duplicates
for death in d:
year_dict.setdefault(death,0) # sets default value of key to 0
year_dict[death] += -1 # will add -1 for each death and sums duplicates
以下代码返回:
{1791: 1, 1796: 1, 1691: 1, 1907: 1, 1999: 1, 2001: 1, 1800: -1, 1803: -1, 1692: -1, 1852: -1, 1980: -1, 2006: -1}
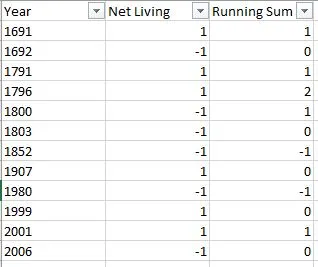
现在我正在寻找一种创建运行总和以查找哪一年有最多人口的方法,例如:
{kind=link}
正如我们所看到的,根据给定的数据集,结果显示1796年有最多的人口。我无法得到运行总和部分,它需要将每个键值与前一个值相加。我尝试了几个不同的循环和枚举,但现在卡住了。一旦我找到解决这个问题的最佳方法,我就会创建一个函数来提高效率。
如果有更有效的方法考虑时间/空间复杂度,请告诉我。我正在尝试学习使用Python实现效率。非常感谢您的帮助!!!