通常在OCR过程中,图像文件会被切成不同的片段,并将每个字符识别为一个单独的片段。例如: 必须被转换成类似这样的图片
必须被转换成类似这样的图片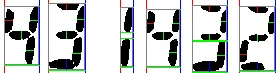 此外,是否有现成的针对亚洲语言如泰卢固语的算法可用于此目的?如果没有,那么英语是如何处理的呢?
此外,是否有现成的针对亚洲语言如泰卢固语的算法可用于此目的?如果没有,那么英语是如何处理的呢?
必须被转换成类似这样的图片
此外,是否有现成的针对亚洲语言如泰卢固语的算法可用于此目的?如果没有,那么英语是如何处理的呢?必须被转换成类似这样的图片
此外,是否有现成的针对亚洲语言如泰卢固语的算法可用于此目的?如果没有,那么英语是如何处理的呢?你可以使用OpenCV轻松完成这个任务。下面是一个示例代码:
import cv2
import numpy as np
# Load the image
img = cv2.imread('sof.png')
# convert to grayscale
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# smooth the image to avoid noises
gray = cv2.medianBlur(gray,5)
# Apply adaptive threshold
thresh = cv2.adaptiveThreshold(gray,255,1,1,11,2)
thresh_color = cv2.cvtColor(thresh,cv2.COLOR_GRAY2BGR)
# apply some dilation and erosion to join the gaps
thresh = cv2.dilate(thresh,None,iterations = 3)
thresh = cv2.erode(thresh,None,iterations = 2)
# Find the contours
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
# For each contour, find the bounding rectangle and draw it
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv2.rectangle(thresh_color,(x,y),(x+w,y+h),(0,255,0),2)
# Finally show the image
cv2.imshow('img',img)
cv2.imshow('res',thresh_color)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出结果将如下图所示:

