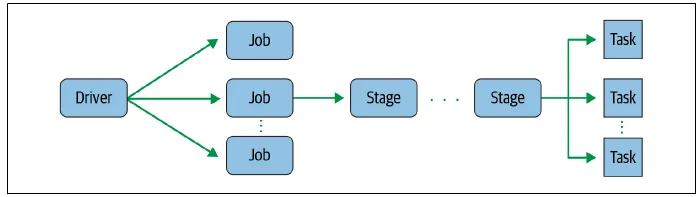
我的理解正确吗?
1. 应用程序: 一个spark提交。
2. 作业: 一旦进行了惰性评估,就会生成一个作业。
3. 阶段: 与shuffle和转换类型有关。我很难理解阶段的边界。
4. 任务: 它是单元操作。每个任务一个转换。每个转换一个任务。
需要帮助来改善这种理解。
1. 应用程序: 一个spark提交。
2. 作业: 一旦进行了惰性评估,就会生成一个作业。
3. 阶段: 与shuffle和转换类型有关。我很难理解阶段的边界。
4. 任务: 它是单元操作。每个任务一个转换。每个转换一个任务。
需要帮助来改善这种理解。