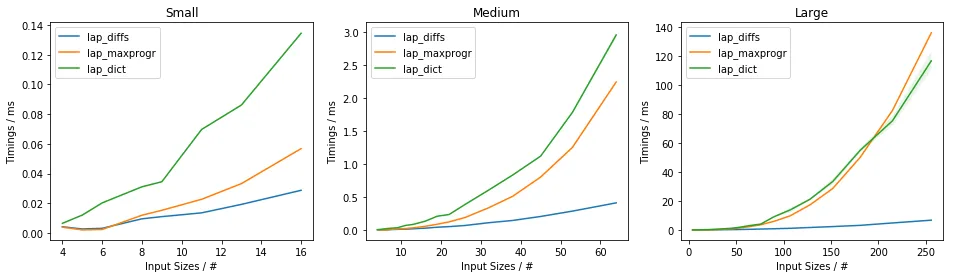
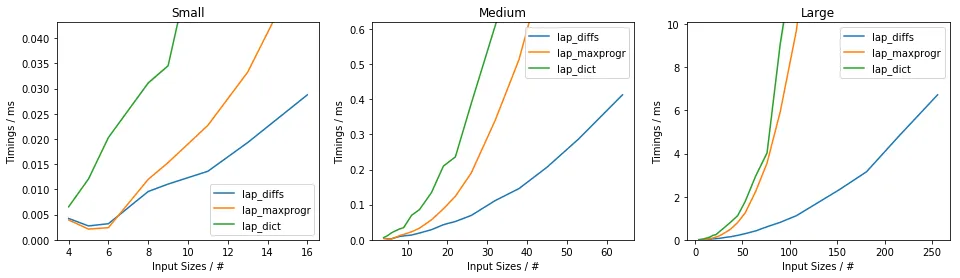
我的做法如下:
1. 我正在创建一个存储所有数字对之间差异和计数的字典
2. 键包含差值,值是一个列表。列表的第一个索引是差值出现的次数,后续索引表示遵循等差数列的数字
我已经编写了以下代码。
例如,如果输入为
但是,我的代码在以下输入
1. 我正在创建一个存储所有数字对之间差异和计数的字典
2. 键包含差值,值是一个列表。列表的第一个索引是差值出现的次数,后续索引表示遵循等差数列的数字
我已经编写了以下代码。
d = {}
for i in range(len(A)-1):
for j in range(i+1, len(A)):
if A[i]-A[j] in d.keys():
d[A[i]-A[j]][0] += 1
d[A[i]-A[j]].append(A[j])
else:
d[A[i]-A[j]] = [2, A[i], A[j]]
# Get the key,value pair having the max value
k,v = max(d.items(), key=lambda k: k[1])
print(v[0])
例如,如果输入为
[20,1,15,3,10,5,8],则输出为4。但是,我的代码在以下输入
[83,20,17,43,52,78,68,45]中失败了。
期望的结果是2,但我得到了3。当我打印我的字典内容时,我发现在字典中有像下面这样的条目:-25: [3, 20, 45, 68], -26: [3, 17, 43, 78], -35: [3, 17, 52, 78]
我不理解为什么它们存在,因为在-25的情况下,68和45的差不是25,而且我在将值添加到字典之前就进行了检查。 请问有人能指出我的代码中的错误吗?
我的完整输出如下:
{63: [2, 83, 20], 66: [2, 83, 17], 40: [2, 83, 43], 31: [2, 83, 52], 5: [2, 83, 78], 15: [2, 83, 68], 38: [2, 83, 45], 3: [2, 20, 17], -23: [2, 20, 43], -32: [2, 20, 52], -58: [2, 20, 78], -48: [2, 20, 68], -25: [3, 20, 45, 68], -26: [3, 17, 43, 78], -35: [3, 17, 52, 78], -61: [2, 17, 78], -51: [2, 17, 68], -28: [2, 17, 45], -9: [2, 43, 52], -2: [2, 43, 45], -16: [2, 52, 68], 7: [2, 52, 45], 10: [2, 78, 68], 33: [2, 78, 45], 23: [2, 68, 45]}