我查看了许多类似的Overflow页面(有些是链接),但没有找到任何有助于这项复杂任务的东西。
我的工作空间中有一系列数据帧,我想循环执行相同的函数(rollmean或其某个版本)在它们所有中运行,然后将结果保存到新的数据帧中。
我编写了几行代码来生成所有数据帧的列表和一个for循环,该循环应迭代每个数据帧上的apply语句;但是,我在尝试实现我所希望实现的所有内容时遇到了问题(包括我的代码和一些示例数据如下):
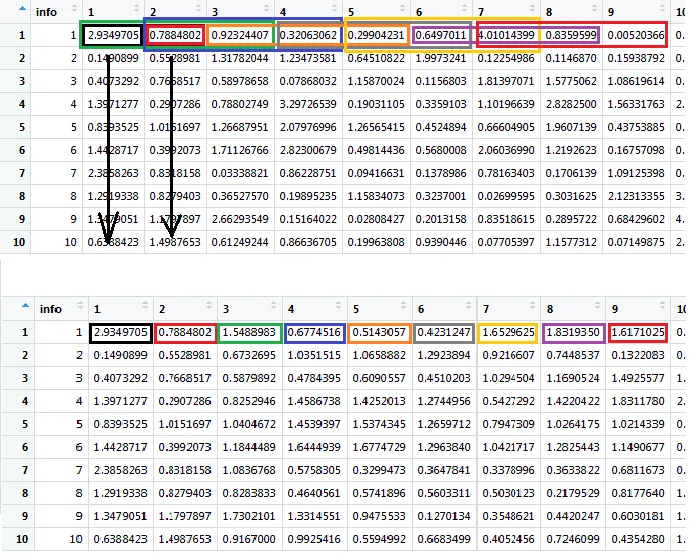
1)我想将rollmean函数限制为除第一列(或前几列)之外的所有列,以便不平均化'info'列。 我还想将这些列添加回输出数据框中。
2)我想将输出保存为新的数据帧(具有唯一名称)。 我不在乎它保存到工作区还是导出为xlsx,因为我已经编写了批量导入代码。
3)理想情况下,我希望结果数据帧与输入具有相同数量的观测结果,而rollmean会缩小您的数据。我也不希望这些变成NA,因此我不想使用fill = NA。 这可以通过编写一个新函数来实现,在rollmean中传递type =“partial”(尽管在我的手中仍会使我的数据缩小1),或从第n + 2项开始对滚动均值进行计算,并将未平均的第n和n + 1项绑定到结果数据框中。任何方法都可以。
(详见图片,它说明了后者的外观)
我的代码只完成了其中的一部分,而且我无法使for循环一起工作,但如果我运行单个数据帧,则可以让其中的部分工作。
非常感谢您的任何建议,因为我已经没有了想法。
#reproducible data frames
a = as.data.frame(cbind(info = 1:10, matrix(rexp(200), 10)))
b = as.data.frame(cbind(info = 1:10, matrix(rexp(200), 10)))
c = as.data.frame(cbind(info = 1:10, matrix(rexp(200), 10)))
colnames(a) = c("info", 1:20)
colnames(b) = c("info", 1:20)
colnames(c) = c("info", 1:20)
#identify all dataframes for looping rollmean
dflist = as.list(ls()[sapply(mget(ls(), .GlobalEnv), is.data.frame)]
#for loop to create rolling average and save as new dataframe
for (j in 1:length(dflist)){
list = as.list(ls()[sapply(mget(ls(), .GlobalEnv), is.data.frame)])
new.names = as.character(unique(list))
smoothed = as.data.frame(
apply(
X = names(list), MARGIN = 1, FUN = rollmean, k = 3, align = 'right'))
assign(new.names[i], smoothed)
}
我曾试过一个嵌套的apply方法,但无法调用rollmean/rollapply函数(类似于此处问题),所以我回到了for循环,但如果有人能够让这个嵌套应用程序工作,那就好了!
图片是理想的输出:顶部是单个输入数据框,其中着色框演示了所有列的滚动平均值,将迭代每一列;底部是理想的输出,颜色反映了上面每个着色窗口的输出位置。