我有一个pyspark 2.0.1。我正在尝试对我的数据框进行分组,并从我的数据框中检索所有字段的值。我发现
z=data1.groupby('country').agg(F.collect_list('names'))
这段代码将为我提供国家和名称属性的值,并为名称属性提供列标题collect_list(names)。但是对于我的工作,我有一个包含约15个列的数据框,并且我将运行一个循环,每次在循环内更改groupby字段,并需要所有剩余字段的输出。请问您能否建议我如何使用collect_list()或任何其他pyspark函数来完成此操作?
我也尝试过这段代码
from pyspark.sql import functions as F
fieldnames=data1.schema.names
names1= list()
for item in names:
if item != 'names':
names1.append(item)
z=data1.groupby('names').agg(F.collect_list(names1))
z.show()
但收到错误信息。
Py4JError: An error occurred while calling z:org.apache.spark.sql.functions.collect_list. Trace: py4j.Py4JException: Method collect_list([class java.util.ArrayList]) does not exist
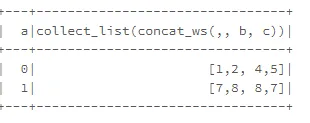
#print itemz=data1.groupby('names').agg(F.collect_list(names1)) z.show()
但是出现了错误信息Py4JError: An error occurred while calling z:org.apache.spark.sql.functions.collect_list. Trace: py4j.Py4JException: Method collect_list([class java.util.ArrayList]) does not exist`。 - Python Learner