这是对这个问题的跟进。
请看这个模式:
它匹配任何由
它可行,请看regex101.com(为更好地演示添加了单词边界)。
问题是:为什么? 在接下来的内容中,字符串的描述(匹配或不匹配)将简单地是一个粗体数字或描述长度的粗体术语,如2n。
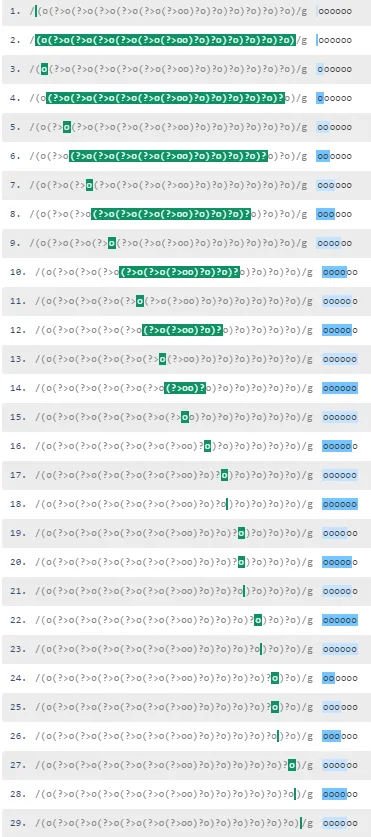
分解如下(添加了空格):
我不明白为什么这里不是匹配2n,而是2的n次方。因为我会将该模式描述为多个未定义数量的“oo”叠在一起。
可视化:
没有递归,“2”是一个匹配:
但是为什么呢?它似乎符合模式。
我得出结论,这不仅仅是重复了简单的模式,否则6将会匹配。
但是根据regular-expressions.info:
“(?P[abc])(?1)(?P>name)”匹配三个字母,就像“(?P[abc])[abc][abc]”一样。
并且
“[abc])(?1){3}”等同于“([abc])[abc]{3}”
因此,它似乎只是重新匹配正则表达式代码,而没有关于捕获组先前匹配的信息。
有人能解释一下,可能还能可视化说明为什么这种模式匹配2n而不是其他任何东西吗?
编辑:
评论中提到:
我怀疑在自身内部引用捕获组实际上是一种受支持的情况。
regular-expressions.info确实提到了这种技术:
如果您在所调用的组内放置调用,您将拥有一个递归捕获组。
请看这个模式:
(o(?1)?o)
它匹配任何由
o组成,长度为2n,n≥1的序列。它可行,请看regex101.com(为更好地演示添加了单词边界)。
问题是:为什么? 在接下来的内容中,字符串的描述(匹配或不匹配)将简单地是一个粗体数字或描述长度的粗体术语,如2n。
分解如下(添加了空格):
( o (?1)? o )
( ) # Capture group 1
o o # Matches an o each at the start and the end of the group
# -> the pattern matches from the outside to the inside.
(?1)? # Again the regex of group 1, or nothing.
# -> Again one 'o' at the start and one at the end. Or nothing.
我不明白为什么这里不是匹配2n,而是2的n次方。因为我会将该模式描述为多个未定义数量的“oo”叠在一起。
可视化:
没有递归,“2”是一个匹配:
oo
一次递归,4是一个匹配:
o o
oo
到目前为止,还是很容易的。
两个递归。显然是错误的,因为模式与6不匹配:
o o
o o
oo
但是为什么呢?它似乎符合模式。
我得出结论,这不仅仅是重复了简单的模式,否则6将会匹配。
但是根据regular-expressions.info:
“(?P[abc])(?1)(?P>name)”匹配三个字母,就像“(?P[abc])[abc][abc]”一样。
并且
“[abc])(?1){3}”等同于“([abc])[abc]{3}”
因此,它似乎只是重新匹配正则表达式代码,而没有关于捕获组先前匹配的信息。
有人能解释一下,可能还能可视化说明为什么这种模式匹配2n而不是其他任何东西吗?
编辑:
评论中提到:
我怀疑在自身内部引用捕获组实际上是一种受支持的情况。
regular-expressions.info确实提到了这种技术:
如果您在所调用的组内放置调用,您将拥有一个递归捕获组。