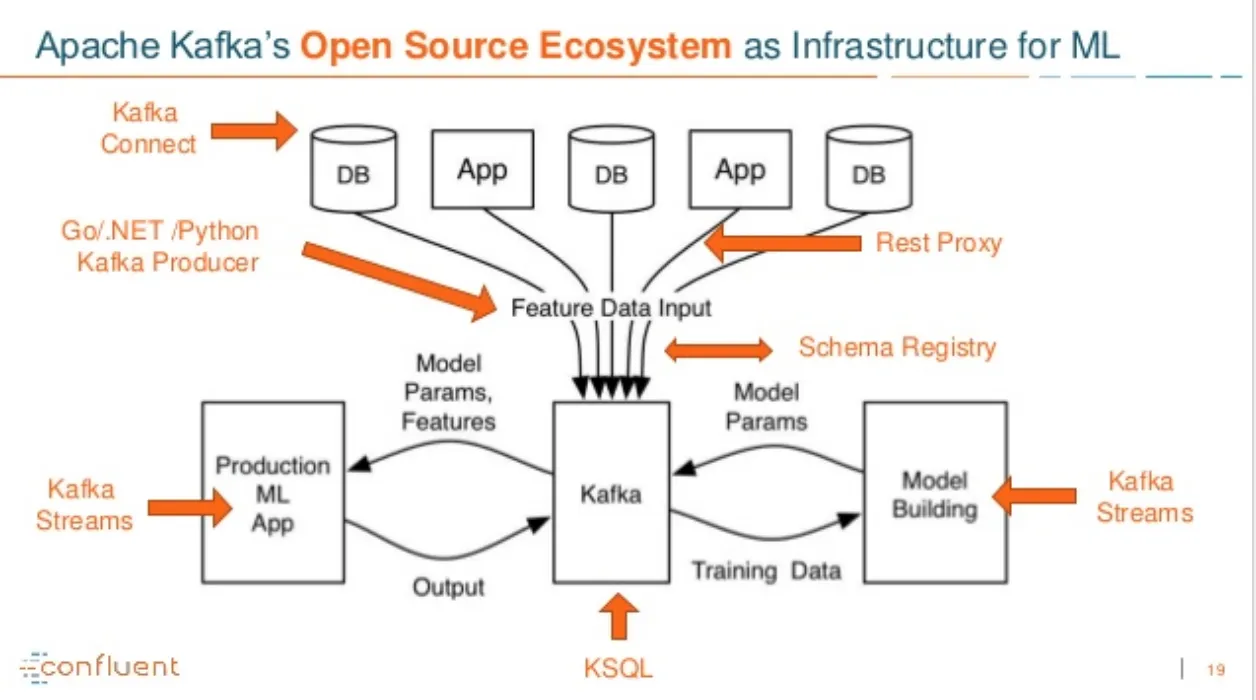
我们有一个用Python编写的预测服务,提供机器学习服务,你可以向它发送一组数据,它会进行异常检测或预测等操作。
我想使用Kafka Streams来处理实时数据。
有两种选择:
1. Kafka Streams作业仅完成ETL功能:加载数据,进行简单转换并将数据保存到Elastic Search。然后定期启动计时器从ES中加载数据,并调用预测服务进行计算,并将结果保存回ES。 2. Kafka Streams作业除了ETL之外,还完成所有其他任务。当Kafka Streams作业完成ETL后,将数据发送到预测服务,并将计算结果保存到Kafka中,消费者将从Kafka中转发结果到ES。
我认为第二种方式更实时,但我不知道在流作业中执行这么多的预测任务是否是一个好主意。
对于这样的应用程序,是否有任何常见模式或建议?
我想使用Kafka Streams来处理实时数据。
有两种选择:
1. Kafka Streams作业仅完成ETL功能:加载数据,进行简单转换并将数据保存到Elastic Search。然后定期启动计时器从ES中加载数据,并调用预测服务进行计算,并将结果保存回ES。 2. Kafka Streams作业除了ETL之外,还完成所有其他任务。当Kafka Streams作业完成ETL后,将数据发送到预测服务,并将计算结果保存到Kafka中,消费者将从Kafka中转发结果到ES。
我认为第二种方式更实时,但我不知道在流作业中执行这么多的预测任务是否是一个好主意。
对于这样的应用程序,是否有任何常见模式或建议?