如果您可以使用外部库,最好使用现代解析器生成器(例如
ANTLR)来完成所有解析工作,并为您的正则表达式提供抽象语法树,即使它是一个相对简单的语言。
否则,如果您需要从头开始编写它,则需要首先确定是否需要令牌化器(或“词法分析器”)。如果您的语言由单个字符标记组成(如您的示例中),那么您可以安全地跳过编写令牌化器并只是在字符串中循环遍历字符。然后,您将不得不编写解析器,这是一个扫描标记列表并构建语法树的大循环。
无论如何,您应该最终得到像这样的语法树,针对您的示例
10(0U1)*:
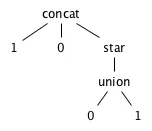
注意,在语法树中,所有括号和隐含的优先规则都被省略了,它们被树结构所代替。
之后,你需要递归地将树翻译成 NFA 图。
以下是
一种可能的实现方式的简要概述。
为每种语法节点类型编写一个翻译方法。该方法将带有其起始和结束的NFA状态作为参数,后者为可选项。该方法将绘制自己的图形片段,并根据需要调用其子元素的翻译方法,并返回其结束状态(该状态可能已被省略为参数,因此对其调用者未知)。
创建一个起始状态,并调用语法树根节点的翻译方法,将起始状态作为其起始状态传递给它。
字面量语法节点(例如你的示例中的0和1)将从其起始状态绘制箭头到其结束状态,如果未提供,则创建一个新的结束状态。
星号节点将调用其子节点的翻译方法,将其自己的起始状态作为子节点的起始状态和结束状态(以便NFA能够“循环”多次)。
连接节点将调用第一个子节点,将其起始状态但没有结束状态传递给它;然后调用第二个子节点,将第一个子节点的结束状态作为起始状态传递给它;以此类推,构建一个子图的单向序列,每个子图对应一个子节点。
您应该已经有了这个想法。
在将NFA图构建为状态的链接结构之后(也许可以将其显示为实际图形,以进行调试或文档目的),您可以将其转换为正式元组并输出。