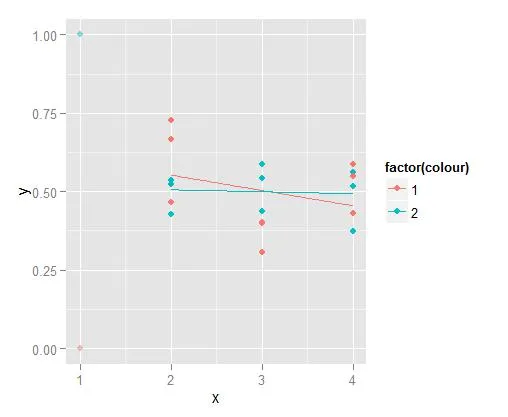
这里有一些数据和一个图:
set.seed(18)
data = data.frame(y=c(rep(0:1,3),rnorm(18,mean=0.5,sd=0.1)),colour=rep(1:2,12),x=rep(1:4,each=6))
ggplot(data,aes(x=x,y=y,colour=factor(colour)))+geom_point()+ geom_smooth(method='lm',formula=y~x,se=F)
从图中可以看出,线性回归受x=1处数值的影响很大。 我能否计算x >= 2的线性回归,但显示x=1时的值(y等于0或1)。 得到的图形除了线性回归外完全相同。它们不会“遭受”自变量=1处数值的影响。