我需要对一个数据框进行缩放。
按行分别将每个元素除以该行中的最大数,但如果该行包含数字1,则不进行操作。
我使用以下方法:
post_df <- df # original dataframe
for(i in 1:nrow(df)){
if (! 1 %in% df[i,]) {
post_df[i,] <- df[i,]/max(df[i,])
}
}
我想知道是否有更快的方法,可以缩短一些时间,因为我在一个大数据框中运行此程序 86000 行 * 500 列。
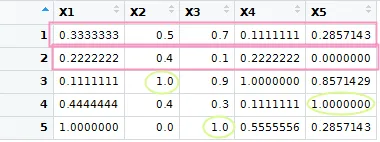
例如:
5 行,5 列
第 1 行:将所有元素除以 0.7
第 2 行:将所有元素除以 0.4
第 3 行:忽略
第 4 行:忽略
第 5 行:忽略