简短回答:使用 not set(a).isdisjoint(b),通常是最快的方法。
测试两个列表 a 和 b 是否有任何相同的元素,通常有四种常见的方法。第一种方法是将它们都转换成集合并检查它们的交集,例如:
bool(set(a) & set(b))
因为在Python中,集合使用哈希表存储,因此搜索它们的时间复杂度是 O(1)(有关Python运算符复杂度的更多信息,请参见此处)。理论上,对于列表中的n和m对象,平均情况下的时间复杂度为O(n+m)。但是:
- 必须首先将列表转换为集合,这可能需要一定的时间。
- 假设您的数据中哈希碰撞很少。
第二种方法是使用生成器表达式对列表进行迭代,例如:
any(i in a for i in b)
这样可以进行就地搜索,因此不会为中间变量分配新的内存。它还会在第一次查找失败时退出。但是,在列表上in运算符始终是O(n)(请参见此处)。
另一个提议的选项是混合方案,通过迭代其中一个列表,将另一个列表转换为集合并在该集合上测试成员资格,如下所示:
a = set(a)
第四种方法是利用(frozen)sets的isdisjoint()方法(请参见这里),例如:
not set(a).isdisjoint(b)
如果您要搜索的元素接近于数组的开始位置(例如,它已经排序),那么生成器表达式是更好的选择,因为集合交集方法必须为中间变量分配新的内存空间:
from timeit import timeit
>>> timeit('bool(set(a) & set(b))', setup="a=list(range(1000));b=list(range(1000))", number=100000)
26.077727576019242
>>> timeit('any(i in a for i in b)', setup="a=list(range(1000));b=list(range(1000))", number=100000)
0.16220548999262974
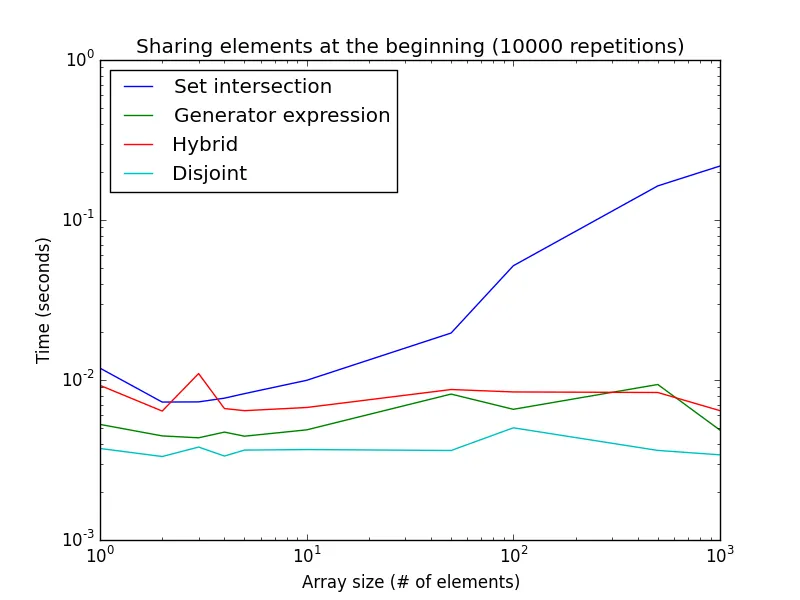
下面是这个示例在不同列表大小下执行时间的图表:
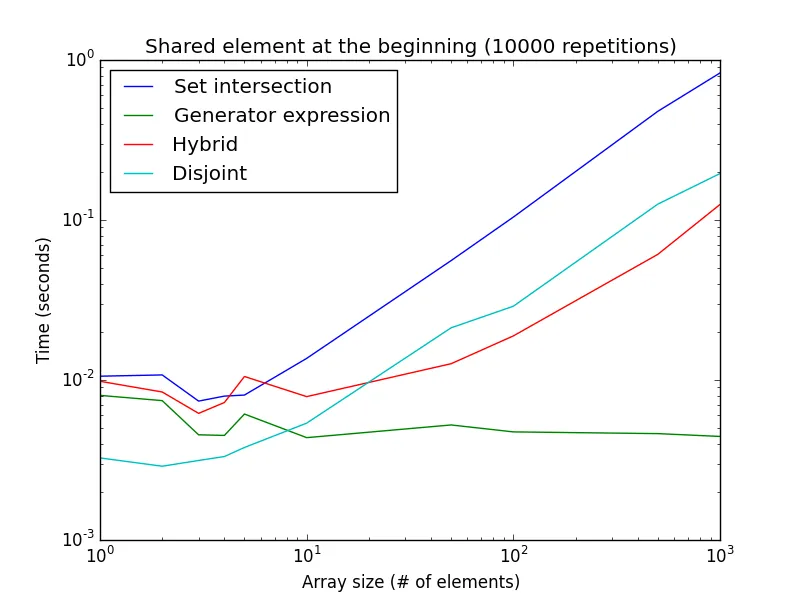
请注意,两个轴都是对数轴。 这代表生成器表达式的最佳情况。 如图所示,isdisjoint()方法对于非常小的列表大小更好,而生成器表达式对于较大的列表大小更好。
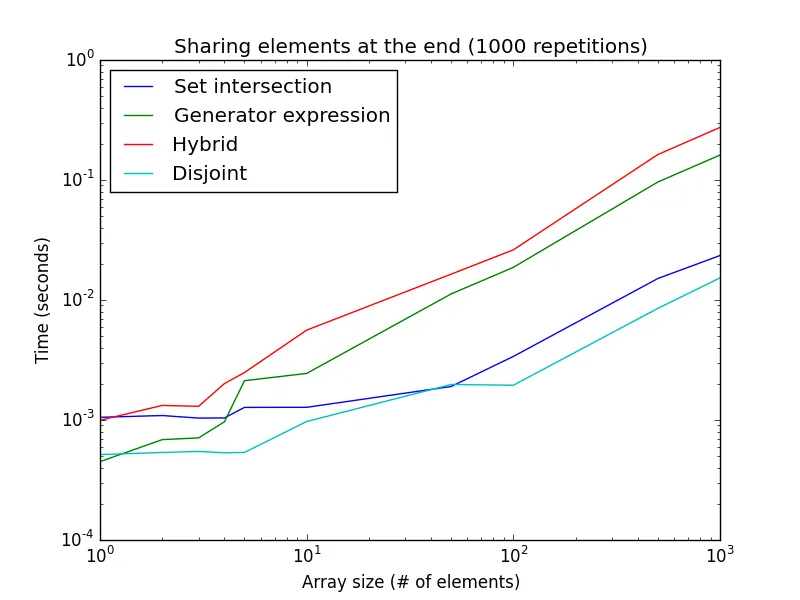
另一方面,由于混合和生成器表达式从开头开始搜索,因此如果共享元素系统地出现在数组末尾(或两个列表没有共享任何值),则与生成器表达式和混合方法相比,“不相交” 和“集合交集”方法会更快。
>>> timeit('any(i in a for i in b)', setup="a=list(range(1000));b=[x+998 for x in range(999,0,-1)]", number=1000))
13.739536046981812
>>> timeit('bool(set(a) & set(b))', setup="a=list(range(1000));b=[x+998 for x in range(999,0,-1)]", number=1000))
0.08102107048034668
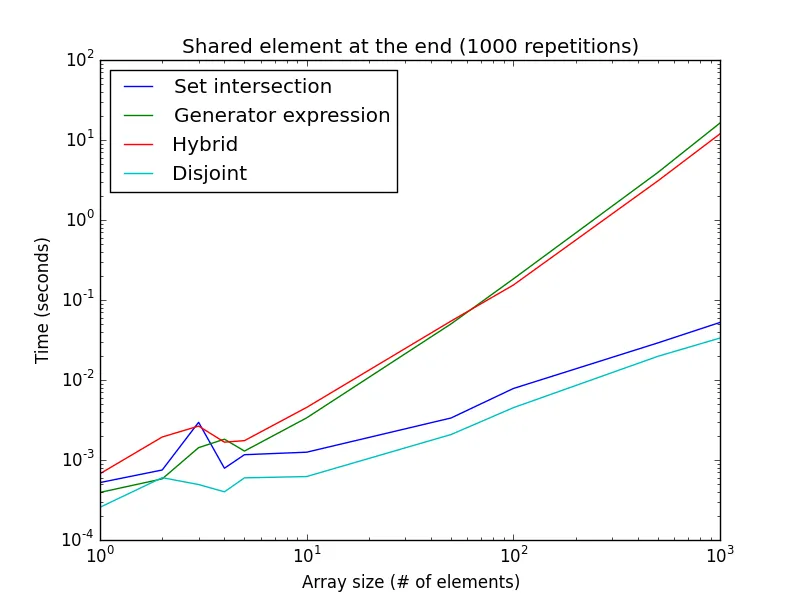
值得注意的是,生成器表达式在更大的列表大小下要慢得多。 这仅针对1000次重复,而不是之前的10万次。 当没有元素共享时,此设置也很好地近似,并且是不相交和集合交集方法的最佳情况。
以下是两个使用随机数进行分析(而不是偏向某种技术的设置):
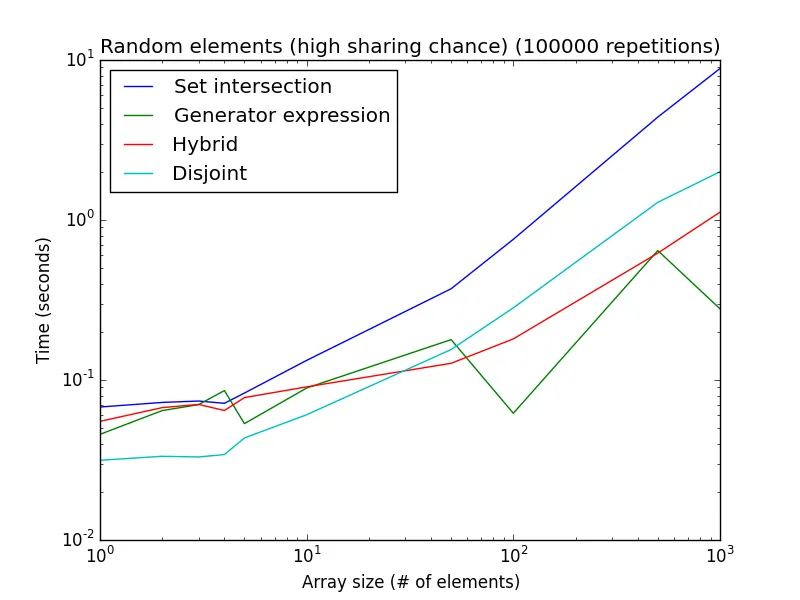
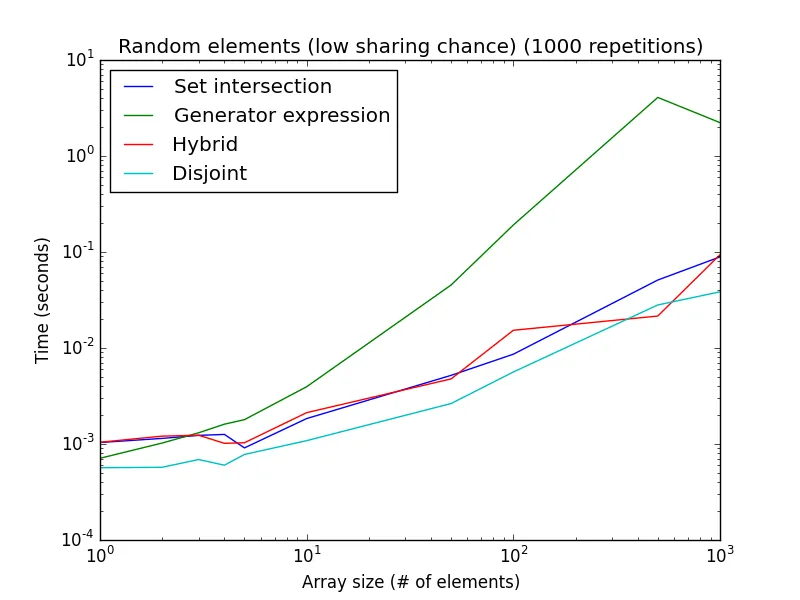
高共享几率:从[1, 2 * len(a)]中随机获取元素。 较低的共享几率:从[1, 1000 * len(a)]中随机获取元素。
到目前为止,本分析假设两个列表的大小相同。 如果存在两个不同大小的列表,例如a要小得多,则isdisjoint()始终更快:
确保a列表更小,否则性能会降低。 在此实验中,a列表大小设置为常数5。
总之:
- 如果列表非常小(<10个元素),则
not set(a).isdisjoint(b)始终是最快的。
- 如果列表中的元素已排序或具有您可以利用的规律结构,则生成器表达式
any(i in a for i in b)在大型列表大小上是最快的;
- 使用
not set(a).isdisjoint(b)测试集合交集,它始终比bool(set(a)&set(b))更快。
- 混合“在列表上迭代,测试集合”
a = set(a); any(i in a for i in b)通常比其他方法慢。
- 当涉及没有共享元素的列表时,生成器表达式和混合方法比另外两种方法要慢得多。
在大多数情况下,使用isdisjoint()方法是最佳选择,因为当没有元素共享时,生成器表达式效率很低,执行时间会很长。