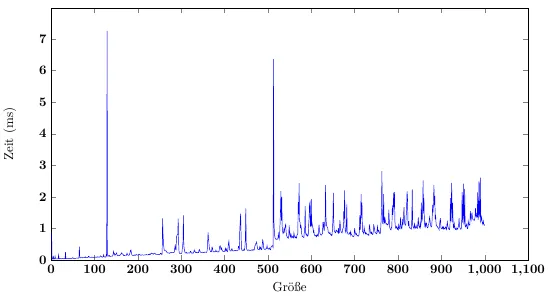
好的,首先让我们看一下图片的简单部分。尖峰是由于重新分配、复制和垃圾回收引起的-这并不令人意外。前几个插入列表的时间异常低,可以通过缓存本地性轻松解释 - 当堆仍适合整个内存时,内存访问可以是随机的,但延迟非常低。一旦堆变得足够大,并且数组长度值(以及列表计数值)足够远离要插入的值,缓存本地性就成为一个显着的影响。在我的32位x86代码中进行测试时,针对缓存本地性进行优化可以将整个测试的性能提高四倍。
然而,虽然这些效应很好地解释了尖峰本身以及尖峰后每个操作所需的时间比之前更长的事实,但它们并没有真正解释随后出现的趋势-没有明显的原因说明为什么插入第600个元素应该比插入第550个元素需要更长时间(假设最后一次调整大小约为512)。分析显示,固定成本相当高,但并没有显示随时间增加而明显增加的东西。
我的测试代码被削减到最基本的内容:
var collections = new List<int>[100000];
for (var i = 0; i < collections.Length; i++)
{
collections[i] = new List<int>();
}
for (var i = 0; i < 1024; i++)
{
for (var j = 0; j < collections.Length; j++)
{
collections[j].Add(i);
}
}
尽管只剩下
Add这一抽象概念,但趋势在测试数据中仍然可见。需要注意的是,我的曲线远不如你的平滑,偏差很大。典型周期大约需要20毫秒,而峰值高达5秒。
好了,现在该看汇编代码了。我的测试代码非常简单(只有内部循环体)。
002D0532 mov eax,dword ptr [ebp-18h]
002D0535 mov ecx,dword ptr [eax+esi*4+8]
002D0539 mov edx,ebx
002D053B cmp dword ptr [ecx],ecx
002D053D call 7311D5F0
collections引用存储在堆栈上。像预期的那样,i和j都在寄存器中,实际上,j在非常方便的esi中。所以,首先我们获取对 collections 的引用,加上 j * 4 + 8来获取实际列表引用,并将其存储在 ecx 中(在我们即将调用的方法中是 this)。i 存储在 ebx 中,但必须移动到 edx 来调用 Add,这并不是什么大问题 - 在两个通用寄存器之间传输值很简单 :) 然后是一个简单的乐观空检查,最后是调用本身。
首先要注意的是没有涉及到分支,因此没有分支错误预测。其次,我们有两个内存访问 - 第一个在堆栈上,几乎保证总是在高速缓存中。第二个更糟糕 - 这就是我们遇到的缓存局部性问题。然而,由此产生的延迟完全取决于数组的长度(和数量),因此应该(也确实)与数组调整大小相关。
现在是时候看一下 Add 方法本身了 :) 记住,ecx 包含列表实例,而 edx 有我们要添加的项。
首先,有通常的方法序言,没有什么特别的。接下来,我们检查数组大小:
8bf1 mov esi, ecx
8bfa mov edi, edx
8b460c mov eax, DWORD PTR [esi+0xc] ; Get the list size
8b5604 mov edx, DWORD PTR [esi+0x4] ; Get the array reference
3bf204 cmp eax, DWORD PTR [edx+0x4] ; size == array.Length?
741c je HandleResize ; Not important for us
我们这里有三个内存访问。前两个基本上是相同的,因为它们加载的值紧密地共享了内存空间。数组只会在第一次数组调整大小之前处于共享内存中,这进一步提高了前几个插入操作的缓存性能。请注意,CPU 在这里几乎无法并行处理,但是这三个内存访问仍然只需要支付一次延迟成本。分支几乎总是被正确预测 - 只有当我们达到数组大小后才会执行它,此后我们将为每个列表执行相同的分支操作一次。
剩下的两个部分是:添加项本身和更新列表的内部版本(以使得列表上进行的任何枚举操作失败):
_items[_size++] = item;
_version++;
汇编语言版本略微冗长 :)
8b5604 mov edx, DWORD PTR [esi+0x4] ; get the array reference again
8b4e0c mov ecx, DWORD PTR [esi+0xc] ; ... and the list size
8d4101 lea eax, [ecx+0x1] ; Funny, but the best way to get size + 1 :)
89460c mov DWORD PTR [esi+0xc], eax ; ... and store the new size back in the list object
3b4a04 cmp ecx, DWORD PTR [edx+0x4] ; Array length check
7318 jae ThrowOutOfRangeException ; If array is shorter than size, throw
897c8a08 mov DWORD PTR [edx+ecx*4+0x8], edi ; Store item in the array
ff4610 inc DWORD PTR [esi+0x10] ; Increase the version
; ... and the epilogue, not important
就这些了。我们有一个分支永远不会被执行(假设单线程;我们已经在先前检查了数组大小)。我们有相当多的访问:四个与列表本身相关的访问(包括两个更新),以及另外两个对数组的访问(包括一个更新)。现在,虽然列表不会出现缓存未命中的情况(它几乎总是已经加载好了),但由于更新而引起的失效将发生。相比之下,在我们的情况下,数组访问将始终导致缓存未命中,唯一的例外是在第一次数组调整大小之前。事实上,您可以看到,首先没有缓存未命中(数组和对象共置,小型),然后有一个未命中(仍然共置,但超出了缓存行的项),然后是两个未命中(长度和项访问均超出了缓存行)。
这确实很有趣(并且可能会从手动优化中获得一点帮助:P),但它再次只为我们提供了性能数据上的“阶梯”。重要的是,这里没有涉及任何分配,因此也不会有GC。
综合所有这些,我得出结论:当不需要数组调整大小时,List.Add确实是O(1)的。对于非常小的数组(以及与其引用共置的数组),有一些额外的优化可以使事情更快,但这在这里并不重要。
因此,您在性能分析数据中看到的趋势必须是环境所致,或直接与性能分析本身相关,或只是选择不当的平均方法。例如,如果我在100,000个列表上运行以下操作:
1.添加前550个项目
2.再添加100个项目
3.再添加100个项目
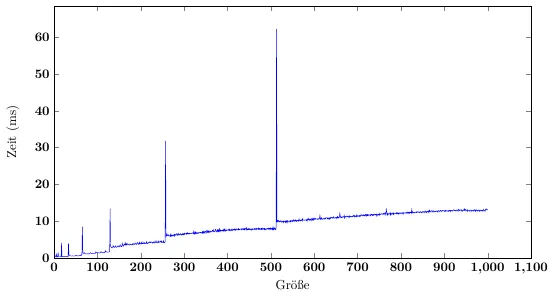
第2步和第3步之间的时间会有所变化,但没有趋势- 2比3更快同样可能(在大约400ms的时间跨度内有大约2ms的差异,因此偏差约为0.5%)。然而,如果我以2100个项目进行“预热”,那么随后的步骤所需的时间几乎是以前的一半。更改列表数量对于每个集合来说没有明显的影响 (当然,只要所有内容都适合物理内存 :))。
好的,在仅仅使用发布模式下的简单运行和对结果数据进行简单采样时就可以轻松看到这一点。因此,我们可以排除掉性能分析效果和统计误差。
但是,环境原因可能是什么呢?
- 除了数组大小调整外,GC根本不参与其中。没有任何分配,而且性能分析器非常清楚地表明,在大小调整之间没有发生GC(虽然这在并发GC中的价值有限 :))。调整GC设置会使所有操作变慢,但仅影响调整大小的峰值及其附近。最重要的是,列表数量(因此堆大小)对趋势没有任何影响,如果GC是原因,这将相当令人惊讶。
- 堆是碎片化的,但非常有序。这使得在内存压力下重新定位具有更小的开销,但同样只影响数组大小调整。无论如何,这并不令人惊讶,实际上已经得到了很好的记录。
所以,看着这一切...我不知道为什么存在这个趋势。然而,请注意,这个趋势绝对不是线性的——随着列表大小的增加,增长迅速减少。从大约15k项开始,趋势完全消失,因此Add在排除数组大小调整的情况下确实是O(1) - 它只在某些大小上表现出奇怪的行为 :)
...除非您预先分配列表。在这种情况下,结果与我基于缓存局部性的预测完全一致。这似乎表明调整大小和GC模式对通常缓存算法的效率有巨大影响(至少在我的CPU上是如此 - 这将有很大不同)。还记得我们谈论过整个Add操作期间产生的缓存未命中吗?有一个技巧 - 如果我们可以在两个循环之间保持足够的缓存行活动状态,则缓存未命中将经常被避免;如果我们假设64字节的缓存行和最佳缓存失效算法,则您将在List成员访问和数组长度访问上没有任何未命中,每16次添加仅在数组上有一个未命中。我们根本不需要数组的其余部分!还有其他几个缓存行(例如列表实例),但数组是最重要的。
现在,让我们来算一下。 十万个集合,在最坏的情况下每个增加2 * 64B的缓存总共增加了12 MiB,而我的缓存为10 MiB - 我几乎可以将所有相关的数组数据都放入缓存中!当然,我不是唯一使用该缓存的应用程序(和线程),因此我们可以预期翻转点略低于理想值 - 让我们看看改变集合数量如何改变我们的结果。
列表预分配为8000项(32 kB),添加2000项,100,100
Lists A B C
400 18 1 1
800 52 2 2
1600 120 6 6
3200 250 12 12
6400 506 25 25
12800 1046 52 53
25600 5821 270 270
哎呀!非常好可见。时间随着列表数量的增加而线性地增加,直到最后一个项目 - 那时我们的缓存用完了。这大约是总共使用了3-8 MiB的缓存 - 很可能是因为我忽略了一些重要的需要缓存的东西,或者操作系统或CPU上的某些优化防止我独占整个缓存等等的结果 :)
在非常小的列表计数中略微不均匀的部分可能与较低级别缓存的慢速溢出有关 - 400项舒适地适合我的L2缓存,800已经有点溢出,1600更多,当我们达到3200时,L2缓存几乎可以完全忽略。
最后进行的测试场景与之前相同,只是添加了4000个项目而不是2000个:
Lists A B C
400 42 1 1
800 110 3 2
1600 253 6 6
3200 502 12 12
6400 1011 25 25
12800 2091 52 53
25600 10395 250 250
如您所见,项目数量对插入时间(每个项目)没有任何影响,整个趋势消失了。
因此,这是由于GC间接引起的(通过代码中次优的分配和GC中破坏缓存局部性的压缩模式),以及直接由于缓存溢出。对于较小的项目计数,当前所需内存的任何给定部分很可能现在就在缓存中。当需要调整数组大小时,大部分缓存内存几乎没用,将被慢慢无效化并替换为更有用的内存 - 但整个内存使用模式与CPU优化的相差甚远。相比之下,通过保留预分配的数组,我们确保一旦将列表保存在内存中,我们也会看到数组长度(奖励1),而已经指向数组末尾的缓存行将对一些循环非常有用(奖励2)。由于没有数组调整大小,这些对象根本不需要在内存中移动,并且存在很好的位置对齐。
List。你知道你可以指定容量吗?如果你非常关心性能,那么这是完全有意义的。否则,你就要依赖于默认大小的好坏了。 - Sinatr