我已经得到了一项证据,可以证明关于0/1背包问题的一个普遍看法是错误的。我真的很难相信自己是对的,因为我找不到任何地方支持我的说法。因此,我将首先陈述我的说法,然后证明它们,我希望任何人都能进一步证实或证伪我的说法。感谢任何合作。
说法:
- 解决背包问题的bnb(分支定界)算法的规模不会与K(背包容量)无关。
- bnb树的完整空间大小始终为O(NK),其中N为物品数量,而不是O(2^N)。
- bnb算法在时间和空间上始终优于 标准 动态规划方法。
前提假设:bnb算法易于产生无效节点(如果剩余容量小于当前物品的重量,则不会扩展它)。此外,bnb算法是以深度优先的方式完成的。
简略证明:
下面是求解背包问题的递归公式:
Value(i,k) = max (Value(i-1,k) , Value(n-1 , k-weight(i)) + value(i)
但是,如果k < weight(i),则Value(i,k) = Value(i-1,k)
现在想象这个例子:
K = 9
N = 3
V W:
5 4
6 5
3 2
现在这里是此问题的动态解决方案和表格:
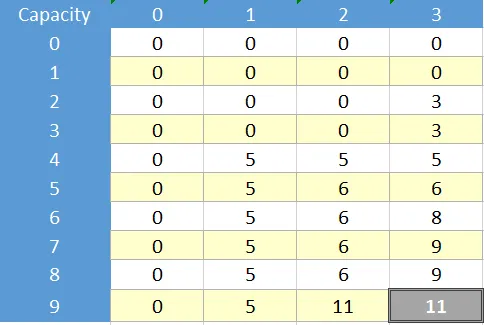
现在假设不论好坏,我们想要仅使用递归公式通过记忆化来解决这个问题,而不使用表格,通过诸如映射/字典或简单数组之类的东西来存储已访问的单元格。为了使用记忆化解决此问题,我们应该解决表示的单元格:
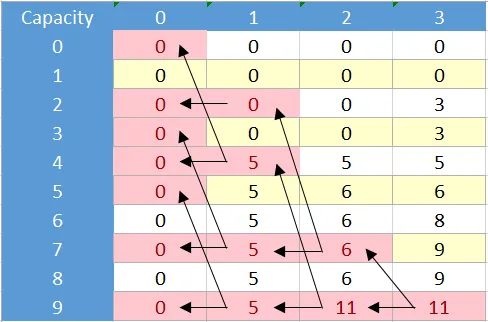
现在这恰好像是我们使用bnb方法获得的树形结构:
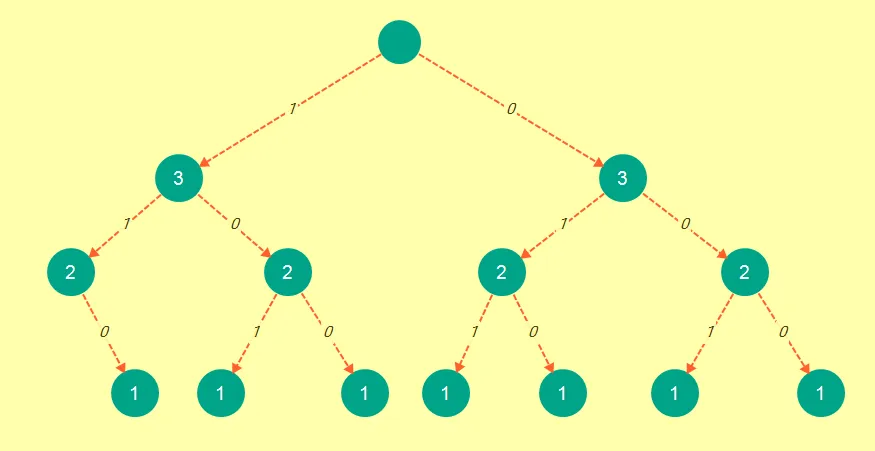
现在考虑证明:
- 记忆化和bnb树具有相同数量的节点
- 记忆化节点取决于表格大小
- 表格大小取决于N和K
- 因此 bnb不独立于K
- 记忆化空间受NK限制,即O(NK)
- 因此 bnb树完整空间(或如果我们按广度优先的方式执行bnb,则空间是O(NK),而不是O(N ^ 2),因为不会构造整个树,它将与记忆化完全相同。
- 记忆化比标准动态规划更省空间。
- bnb比动态规划更节省空间(即使以广度优先的方式进行)
- 简单的bnb(仅消除不可行节点)的时间比记忆化好。
- 如果不考虑记忆查找,那么它比动态规划好。
- 因此bnb算法在时间和空间上总是优于动态规划。
问题:
如果我的证明正确,那么会出现一些有趣的问题:
- 为什么要使用动态规划?在我看来,在dp背包中最好的方法就是只保留最后两列,并且如果您从下到上填充它,可以进一步改进为一列,但是(如果上述断言正确)仍然无法击败bnb方法,尽管它使用O(K)空间。
- 如果我们将relaxation pruning集成到bnb中,我们仍然可以说bnb更好(与时间有关吗)?
附言:很抱歉文章太长了!
编辑:
由于两个答案都集中在记忆化上,我想澄清一下,我根本没有关注这个!我只是使用记忆化作为一种技术来证明我的断言。我的主要重点是分支限界技术与动态规划的比较,以下是另一个问题的完整示例,通过bnb +松弛解决(来源:Coursera - 离散优化):
{kind=link}