我正在寻找一种在Docker容器内部使用GPU的方法。
由于容器将执行任意代码,因此我不想使用特权模式。
有什么建议吗?
从以前的研究中,我了解到
run -v和/或LXC cgroup是可行的方法,但我不确定如何确切地实现这一点。run -v和/或LXC cgroup是可行的方法,但我不确定如何确切地实现这一点。由于大部分已有的答案已经过时,因此我将提供最新的答案。
早于 Docker 19.03 版本的需要使用 nvidia-docker2 和 --runtime=nvidia 标志。
从 Docker 19.03 开始,您需要安装 nvidia-container-toolkit 包,然后使用 --gpus all 标志。
以下是基础知识:
包安装
根据 Github 上的官方文档安装 nvidia-container-toolkit 包。
对于基于 Redhat 的操作系统,请执行以下一组命令:
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
$ sudo yum install -y nvidia-container-toolkit
$ sudo systemctl restart docker
# Add the package repositories
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo systemctl restart docker
使用GPU支持运行Docker
docker run --name my_all_gpu_container --gpus all -t nvidia/cuda
--gpus all用于将所有可用的GPU分配给Docker容器。docker run --name my_first_gpu_container --gpus device=0 nvidia/cuda
或者
docker run --name my_first_gpu_container --gpus '"device=0"' nvidia/cuda
nvidia-container-toolkit)和官方文档(nvidia-docker2)之间的软件包安装差异。 - Atralb$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9
$ sudo sh -c "echo deb https://get.docker.com/ubuntu docker main > /etc/apt/sources.list.d/docker.list"
$ sudo apt-get update && sudo apt-get install lxc-docker
ls -la /dev | grep nvidia
crw-rw-rw- 1 root root 195, 0 Oct 25 19:37 nvidia0
crw-rw-rw- 1 root root 195, 255 Oct 25 19:37 nvidiactl
crw-rw-rw- 1 root root 251, 0 Oct 25 19:37 nvidia-uvm
我创建了一个docker镜像,其中预先安装了cuda驱动程序。 如果您想知道如何构建此镜像,则可以在dockerhub上找到dockerfile。
您需要根据自己的nvidia设备自定义此命令。 这是对我有效的命令:
$ sudo docker run -ti --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidiactl:/dev/nvidiactl --device /dev/nvidia-uvm:/dev/nvidia-uvm tleyden5iwx/ubuntu-cuda /bin/bash
此操作应在您刚启动的Docker容器中运行。
安装CUDA示例:
$ cd /opt/nvidia_installers
$ ./cuda-samples-linux-6.5.14-18745345.run -noprompt -cudaprefix=/usr/local/cuda-6.5/
构建 deviceQuery 示例:
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery
$ make
$ ./deviceQuery
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 6.5, CUDA Runtime Version = 6.5, NumDevs = 1, Device0 = GRID K520
Result = PASS
./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
cudaGetDeviceCount returned 38
-> no CUDA-capable device is detected
Result = FAIL这是因为主机和容器中的CUDA库不匹配导致的吗? - brunetto好的,我终于成功地做到了,而且没有使用--privileged模式。
我正在运行Ubuntu服务器14.04,使用最新的CUDA(适用于Linux 13.04 64位的6.0.37版本)。
在主机上安装NVIDIA驱动程序和CUDA。(这可能有点棘手,因此我建议您按照此指南进行操作:https://askubuntu.com/questions/451672/installing-and-testing-cuda-in-ubuntu-14-04)
注意:非常重要的是,您要保留用于主机CUDA安装的文件。
我们需要使用lxc驱动程序运行Docker守护程序,以便能够修改配置并使容器可以访问设备。
一次性使用:
sudo service docker stop
sudo docker -d -e lxc
永久配置 修改位于 /etc/default/docker 的 docker 配置文件 通过添加 '-e lxc' 修改 DOCKER_OPTS 行 这是我的修改后的行
DOCKER_OPTS="--dns 8.8.8.8 --dns 8.8.4.4 -e lxc"
然后使用以下命令重启守护程序:
sudo service docker restart
docker info
执行驱动器行应该像这样:
Execution Driver: lxc-1.0.5
这里是一个基本的Dockerfile,用于构建兼容CUDA的镜像。
FROM ubuntu:14.04
MAINTAINER Regan <https://dev59.com/Pl8e5IYBdhLWcg3w9-Rs
RUN apt-get update && apt-get install -y build-essential
RUN apt-get --purge remove -y nvidia*
ADD ./Downloads/nvidia_installers /tmp/nvidia > Get the install files you used to install CUDA and the NVIDIA drivers on your host
RUN /tmp/nvidia/NVIDIA-Linux-x86_64-331.62.run -s -N --no-kernel-module > Install the driver.
RUN rm -rf /tmp/selfgz7 > For some reason the driver installer left temp files when used during a docker build (i don't have any explanation why) and the CUDA installer will fail if there still there so we delete them.
RUN /tmp/nvidia/cuda-linux64-rel-6.0.37-18176142.run -noprompt > CUDA driver installer.
RUN /tmp/nvidia/cuda-samples-linux-6.0.37-18176142.run -noprompt -cudaprefix=/usr/local/cuda-6.0 > CUDA samples comment if you don't want them.
RUN export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 > Add CUDA library into your PATH
RUN touch /etc/ld.so.conf.d/cuda.conf > Update the ld.so.conf.d directory
RUN rm -rf /temp/* > Delete installer files.
首先需要确定与设备关联的主要编号。最简单的方法是执行以下命令:
ls -la /dev | grep nvidia
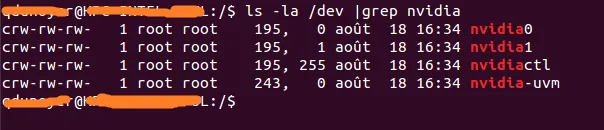 正如您所看到的,在组和日期之间有一组2个数字。
这两个数字称为主要号码和次要号码(按照这个顺序编写),并设计了设备。
我们只会使用主要号码以方便操作。
正如您所看到的,在组和日期之间有一组2个数字。
这两个数字称为主要号码和次要号码(按照这个顺序编写),并设计了设备。
我们只会使用主要号码以方便操作。所以,如果我想启动一个容器(假设您的镜像名称为cuda)。--lxc-conf='lxc.cgroup.devices.allow = c [major number]:[minor number or *] rwm'
docker run -ti --lxc-conf='lxc.cgroup.devices.allow = c 195:* rwm' --lxc-conf='lxc.cgroup.devices.allow = c 243:* rwm' cuda
--device选项,允许容器访问主机的设备。然而,我尝试使用--device=/dev/nvidia0来允许Docker容器运行CUDA,但失败了。 - shiquanwang--device 暴露了所有的 /dev/nvidia0、/dev/nvidia1、/dev/nvidiactl 和 /dev/nvidia-uvm。但我不知道原因。 - shiquanwang我们刚刚发布了一个实验性的GitHub代码库,这将简化在Docker容器中使用NVIDIA GPU的过程。
最近NVIDIA的改进实现了一种更加强大的方法来完成这个任务。
基本上,他们已经找到了一种方法来避免在容器内安装CUDA / GPU驱动程序,并使其与主机内核模块匹配的需要。
相反,驱动程序位于主机上,容器不需要它们。目前需要使用修改过的docker-cli。
这很棒,因为现在容器变得更加便携。
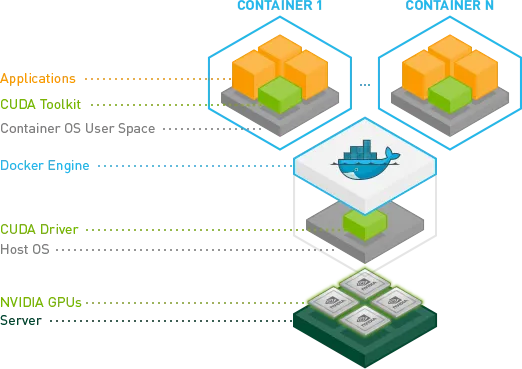
在Ubuntu上进行快速测试:
# Install nvidia-docker and nvidia-docker-plugin
wget -P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker_1.0.1-1_amd64.deb
sudo dpkg -i /tmp/nvidia-docker*.deb && rm /tmp/nvidia-docker*.deb
# Test nvidia-smi
nvidia-docker run --rm nvidia/cuda nvidia-smi
更多详情请查看: GPU-Enabled Docker Container 和: https://github.com/NVIDIA/nvidia-docker
安装Docker https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-16-04
构建以下包含Nvidia驱动程序和CUDA工具包的镜像
Dockerfile
FROM ubuntu:16.04
MAINTAINER Jonathan Kosgei <jonathan@saharacluster.com>
# A docker container with the Nvidia kernel module and CUDA drivers installed
ENV CUDA_RUN https://developer.nvidia.com/compute/cuda/8.0/prod/local_installers/cuda_8.0.44_linux-run
RUN apt-get update && apt-get install -q -y \
wget \
module-init-tools \
build-essential
RUN cd /opt && \
wget $CUDA_RUN && \
chmod +x cuda_8.0.44_linux-run && \
mkdir nvidia_installers && \
./cuda_8.0.44_linux-run -extract=`pwd`/nvidia_installers && \
cd nvidia_installers && \
./NVIDIA-Linux-x86_64-367.48.run -s -N --no-kernel-module
RUN cd /opt/nvidia_installers && \
./cuda-linux64-rel-8.0.44-21122537.run -noprompt
# Ensure the CUDA libs and binaries are in the correct environment variables
ENV LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-8.0/lib64
ENV PATH=$PATH:/usr/local/cuda-8.0/bin
RUN cd /opt/nvidia_installers &&\
./cuda-samples-linux-8.0.44-21122537.run -noprompt -cudaprefix=/usr/local/cuda-8.0 &&\
cd /usr/local/cuda/samples/1_Utilities/deviceQuery &&\
make
WORKDIR /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo docker run -ti --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidiactl:/dev/nvidiactl --device /dev/nvidia-uvm:/dev/nvidia-uvm <built-image> ./deviceQuery
您应该看到类似于以下输出:
deviceQuery,CUDA驱动程序=CUDART,CUDA驱动程序版本=8.0,CUDA运行时版本=8.0,NumDevs = 1,Device0 = GRID K520
Result = PASS
我的目标是制作一个支持CUDA的Docker镜像,而不使用nvidia/cuda作为基础镜像。因为我有一些自定义的jupyter镜像,并且我希望以此为基础。
主机已经安装了nvidia驱动程序、CUDA工具包和nvidia-container-toolkit。请参考官方文档和Rohit的答案。
使用nvidia-smi在主机上测试是否正确安装了nvidia驱动程序和CUDA工具包,它应该显示正确的“驱动版本”和“CUDA版本”,并显示GPU信息。
使用docker run --rm --gpus all nvidia/cuda:latest nvidia-smi测试是否正确安装了nvidia-container-toolkit。
我找到了我认为是nvidia/cuda的官方Dockerfile 这里 我将其“展开”,将内容附加到我的Dockerfile中,并测试它工作正常:
FROM sidazhou/scipy-notebook:latest
# FROM ubuntu:18.04
###########################################################################
# See https://gitlab.com/nvidia/container-images/cuda/-/blob/master/dist/10.1/ubuntu18.04-x86_64/base/Dockerfile
# See https://sarus.readthedocs.io/en/stable/user/custom-cuda-images.html
###########################################################################
USER root
###########################################################################
# base
RUN apt-get update && apt-get install -y --no-install-recommends \
gnupg2 curl ca-certificates && \
curl -fsSL https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub | apt-key add - && \
echo "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 /" > /etc/apt/sources.list.d/cuda.list && \
echo "deb https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 /" > /etc/apt/sources.list.d/nvidia-ml.list && \
apt-get purge --autoremove -y curl \
&& rm -rf /var/lib/apt/lists/*
ENV CUDA_VERSION 10.1.243
ENV CUDA_PKG_VERSION 10-1=$CUDA_VERSION-1
# For libraries in the cuda-compat-* package: https://docs.nvidia.com/cuda/eula/index.html#attachment-a
RUN apt-get update && apt-get install -y --no-install-recommends \
cuda-cudart-$CUDA_PKG_VERSION \
cuda-compat-10-1 \
&& ln -s cuda-10.1 /usr/local/cuda && \
rm -rf /var/lib/apt/lists/*
# Required for nvidia-docker v1
RUN echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf
ENV PATH /usr/local/nvidia/bin:/usr/local/cuda/bin:${PATH}
ENV LD_LIBRARY_PATH /usr/local/nvidia/lib:/usr/local/nvidia/lib64
###########################################################################
#runtime next
ENV NCCL_VERSION 2.7.8
RUN apt-get update && apt-get install -y --no-install-recommends \
cuda-libraries-$CUDA_PKG_VERSION \
cuda-npp-$CUDA_PKG_VERSION \
cuda-nvtx-$CUDA_PKG_VERSION \
libcublas10=10.2.1.243-1 \
libnccl2=$NCCL_VERSION-1+cuda10.1 \
&& apt-mark hold libnccl2 \
&& rm -rf /var/lib/apt/lists/*
# apt from auto upgrading the cublas package. See https://gitlab.com/nvidia/container-images/cuda/-/issues/88
RUN apt-mark hold libcublas10
###########################################################################
#cudnn7 (not cudnn8) next
ENV CUDNN_VERSION 7.6.5.32
RUN apt-get update && apt-get install -y --no-install-recommends \
libcudnn7=$CUDNN_VERSION-1+cuda10.1 \
&& apt-mark hold libcudnn7 && \
rm -rf /var/lib/apt/lists/*
ENV NVIDIA_VISIBLE_DEVICES all
ENV NVIDIA_DRIVER_CAPABILITIES all
ENV NVIDIA_REQUIRE_CUDA "cuda>=10.1"
###########################################################################
#docker build -t sidazhou/scipy-notebook-gpu:latest .
#docker run -itd -gpus all\
# -p 8888:8888 \
# -p 6006:6006 \
# --user root \
# -e NB_UID=$(id -u) \
# -e NB_GID=$(id -g) \
# -e GRANT_SUDO=yes \
# -v ~/workspace:/home/jovyan/work \
# --name sidazhou-jupyter-gpu \
# sidazhou/scipy-notebook-gpu:latest
#docker exec sidazhou-jupyter-gpu python -c "import tensorflow as tf; print(tf.config.experimental.list_physical_devices('GPU'))"
USER。这可能会导致图像出现问题。执行USER $NB_UID应该可以重置它。此外,我认为可以通过使用conda来简化此过程,因为它已经在scipy-notebook镜像中可用。 - Konrad Rudolphsidazhou/scipy-notebook 的 Dockerfile 源代码呢? - Konrad Rudolphjupyter/scipy-notebook 的,安装了一些额外的包。虽然我认为这与本次讨论无关。 - Sida Zhoujupyter/scipy-notebook 一样那就好办了,是的。我自己还没有让它工作起来,但我已经一个多月没有接触这个项目了,也不记得是否尝试过以 scipy-notebook 为基础构建了。 - Konrad Rudolph要在docker容器中使用GPU,可以使用Nvidia-docker而不是原生的Docker。要安装Nvidia docker,请使用以下命令。
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-
docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker
sudo pkill -SIGHUP dockerd # Restart Docker Engine
sudo nvidia-docker run --rm nvidia/cuda nvidia-smi # finally run nvidia-smi in the same container
这个脚本非常方便,因为它处理了所有配置和设置。在带有 GPU 的 X 上运行 docker 镜像就像这样简单:硬件加速
使用 -g, --gpu 选项可以实现 OpenGL 的硬件加速。
在大多数情况下,这将与主机上的开源驱动程序自动配合使用。否则,请查看维基百科:特性依赖关系。 闭源 NVIDIA 驱动程序需要一些设置,并支持较少的 x11docker X 服务器选项。
x11docker --gpu imagename
x11docker 的主要用途似乎是图形界面,并提供启用 GPU 加速的选项。 - Babyburgernvidia/cuda基础映像。如果不确定要选择哪个版本,请选择最新和最大的版本(如果进行深度学习,则包含cuDNN)。mkdir ~/cuda11
cd ~/cuda11
echo "FROM nvidia/cuda:11.0-cudnn8-devel-ubuntu18.04" > Dockerfile
echo "CMD [\"/bin/bash\"]" >> Dockerfile
docker build --tag mirekphd/cuda11 .
docker run --rm -it --gpus 1 mirekphd/cuda11 nvidia-smi
nvidia-smi,请勿尝试在容器中安装它 - 它已经在带有 NVIDIA GPU 驱动程序的主机上安装,并且如果 docker 有 GPU 访问权限,则应该从主机提供给容器系统。+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.57 Driver Version: 450.57 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:01:00.0 On | N/A |
| 0% 50C P8 17W / 280W | 409MiB / 11177MiB | 7% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
前提条件
首先在主机上安装支持最新CUDA版本的适当NVIDIA驱动程序(从NVIDIA Driver Downloads下载),然后运行mv driver-file.run driver-file.sh && chmod +x driver-file.sh && ./driver-file.sh。自CUDA 10.1以来,它们已经向前兼容。
通过安装sudo apt get update && sudo apt get install nvidia-container-toolkit启用docker中的GPU访问(然后使用sudo systemctl restart docker重新启动docker守护程序)。