我该如何为RetrievalQA.from_chain_type添加内存?或者,我该如何为ConversationalRetrievalChain添加自定义提示?
在过去的两周里,我一直在尝试制作一个可以与文档聊天的聊天机器人(不仅仅是语义搜索/问答,还有记忆),并且带有自定义提示。我尝试了所有链的组合,到目前为止,最接近的是ConversationalRetrievalChain,但没有自定义提示,以及RetrievalQA.from_chain_type,但没有内存。
我该如何为RetrievalQA.from_chain_type添加内存?或者,我该如何为ConversationalRetrievalChain添加自定义提示?
在过去的两周里,我一直在尝试制作一个可以与文档聊天的聊天机器人(不仅仅是语义搜索/问答,还有记忆),并且带有自定义提示。我尝试了所有链的组合,到目前为止,最接近的是ConversationalRetrievalChain,但没有自定义提示,以及RetrievalQA.from_chain_type,但没有内存。
更新: 本帖回答了OP问题的第一部分:
如何向RetrievalQA.from_chain_type添加内存?
有关第二部分,请参见@andrew_reece's answer
或者,如何向ConversationalRetrievalChain添加自定义提示?
原文:
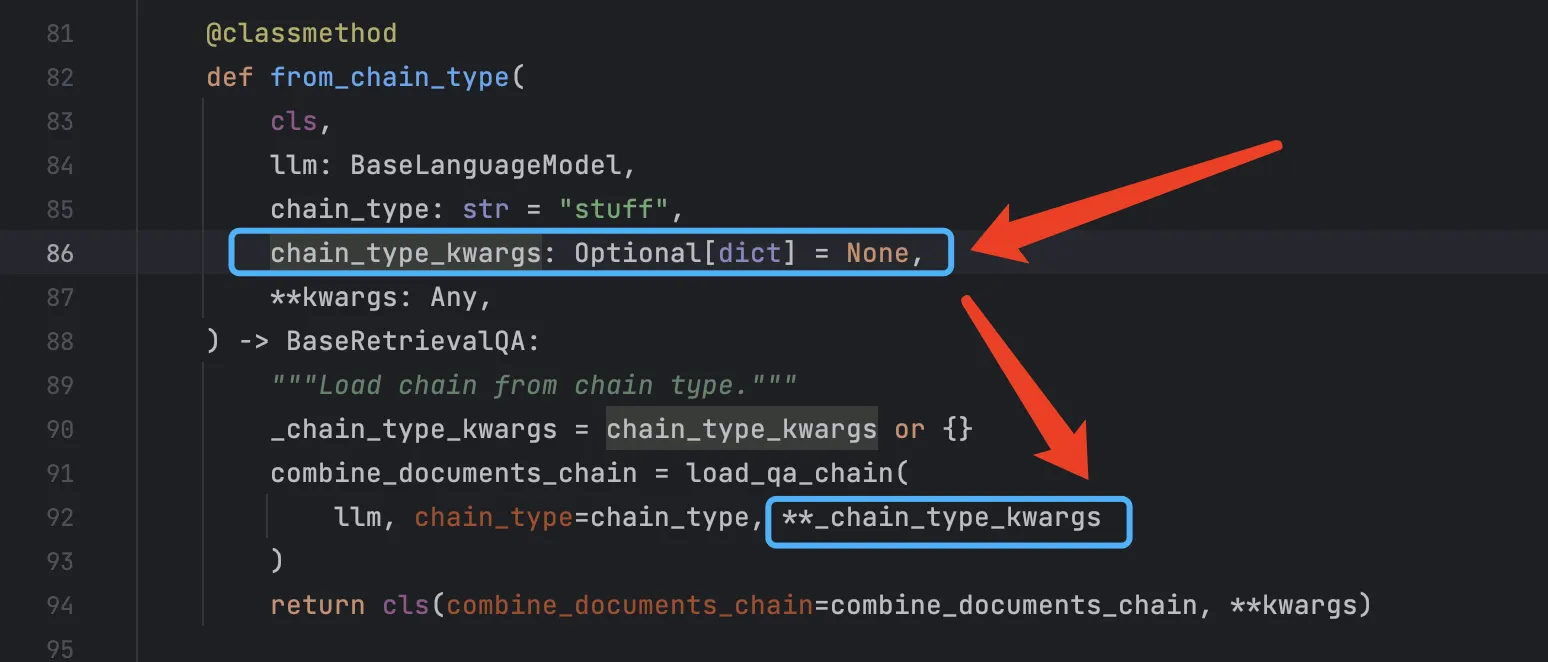
您是否尝试传递chain_type_kwargs(底部是源代码的截图,可供快速参考)?
文档没有很容易地让人理解其内部原理,但是这里有一个可以实现您目标的方法。
您可以在此处找到笔记本电脑 GitHub Link 的设置
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferMemory
from langchain import PromptTemplate
from langchain.retrievers import TFIDFRetriever
retriever = TFIDFRetriever.from_texts(
["Our client, a gentleman named Jason, has a dog whose name is Dobby",
"Jason has a good friend called Emma",
"Emma has a cat whose name is Sullivan"])
然后定义您的自定义提示:
template = """
Use the following context (delimited by <ctx></ctx>) and the chat history (delimited by <hs></hs>) to answer the question:
------
<ctx>
{context}
</ctx>
------
<hs>
{history}
</hs>
------
{question}
Answer:
"""
prompt = PromptTemplate(
input_variables=["history", "context", "question"],
template=template,
)
'history' 和 'question' ,因为在设置内存时需要匹配这些变量。qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type='stuff',
retriever=retriever,
verbose=True,
chain_type_kwargs={
"verbose": True,
"prompt": prompt,
"memory": ConversationBufferMemory(
memory_key="history",
input_key="question"),
}
)
现在你可以调用 qa.run({"query": "谁是客户的朋友?"})
"客户的朋友是Emma。"
然后调用 qa.run("她的宠物叫什么名字?")
"Emma的宠物名字是Sullivan。"
要检查和验证记忆/聊天历史: qa.combine_documents_chain.memory
ConversationBufferMemory(chat_memory=ChatMessageHistory(messages=[HumanMessage(content="谁是客户的朋友?", additional_kwargs={}), AIMessage(content="客户的朋友是Emma。", additional_kwargs={}), HumanMessage(content="她的宠物叫什么名字?", additional_kwargs={}), AIMessage(content="Emma的宠物名字是Sullivan。", additional_kwargs={})]), output_key=None, input_key='question', return_messages=False, human_prefix='人类', ai_prefix='AI', memory_key='history')
这里有一个使用ConversationalRetrievalChain的解决方案,带有内存和自定义提示,使用默认的'stuff'链类型。
这里有两个可以自定义的提示。首先是将对话历史记录与当前用户输入压缩的提示(condense_question_prompt),其次是指示Chain如何向用户返回最终响应的提示(发生在combine_docs_chain中)。
from langchain import PromptTemplate
# note that the input variables ('question', etc) are defaults, and can be changed
condense_prompt = PromptTemplate.from_template(
('Do X with user input ({question}), and do Y with chat history ({chat_history}).')
)
combine_docs_custom_prompt = PromptTemplate.from_template(
('Write a haiku about a dolphin.\n\n'
'Completely ignore any context, such as {context}, or the question ({question}).')
)
ConversationalRetrievalChain。from langchain.llms import OpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = ConversationalRetrievalChain.from_llm(
OpenAI(temperature=0),
vectorstore.as_retriever(), # see below for vectorstore definition
memory=memory,
condense_question_prompt=condense_prompt,
combine_docs_chain_kwargs=dict(prompt=combine_docs_custom_prompt)
)
_load_stuff_chain(),它允许使用可选的prompt kwarg(这就是我们可以自定义的内容)。这用于设置LLMChain,然后初始化StuffDocumentsChain。chain("What color is mentioned in the document about cats?")['answer']
#'\n\nDolphin leaps in sea\nGraceful and playful in blue\nJoyful in the waves'
而且内存正常工作:
chain.memory
#ConversationBufferMemory(chat_memory=ChatMessageHistory(messages=[HumanMessage(content='What color is mentioned in the document about cats?', additional_kwargs={}), AIMessage(content='\n\nDolphin leaps in sea\nGraceful and playful in blue\nJoyful in the waves', additional_kwargs={})]), output_key=None, input_key=None, return_messages=True, human_prefix='Human', ai_prefix='AI', memory_key='chat_history')
使用短暂的ChromaDB实例的示例向量存储数据集:
from langchain.vectorstores import Chroma
from langchain.document_loaders import DataFrameLoader
from langchain.embeddings.openai import OpenAIEmbeddings
data = {
'index': ['001', '002', '003'],
'text': [
'title: cat friend\ni like cats and the color blue.',
'title: dog friend\ni like dogs and the smell of rain.',
'title: bird friend\ni like birds and the feel of sunshine.'
]
}
df = pd.DataFrame(data)
loader = DataFrameLoader(df, page_content_column="text")
docs = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(docs, embeddings)
#这是函数
def qasystem(query):
loader = TextLoader("details.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(documents)
vectordb = Chroma.from_documents(
documents,
embedding=OpenAIEmbeddings(),
persist_directory='./data'
)
vectordb.persist()
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a
standalone question without changing the content in given question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
condense_question_prompt_template = PromptTemplate.from_template(_template)
prompt_template = """You are helpful information giving QA System and make sure you don't answer anything
not related to following context. You are always provide useful information & details available in the given context. Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
qa_prompt = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI(temperature=0.1)
question_generator = LLMChain(llm=llm, prompt=condense_question_prompt_template, memory=memory)
doc_chain = load_qa_chain(llm, chain_type="stuff", prompt=qa_prompt)
qa_chain = ConversationalRetrievalChain(
retriever=vectordb.as_retriever(search_kwargs={'k': 6}),
question_generator=question_generator,
combine_docs_chain=doc_chain,
memory=memory,
)
chat_history = []
while True:
result = qa_chain({'question': question, 'chat_history': chat_history})
response = result['answer']
chat_history.append((question, response))
return result['answer'
ConversationBufferMemory时,我正在使用一个非常简单的测试来确认我的聊天机器人是否正常工作,即询问聊天机器人“我最初提出的第一个问题是什么”。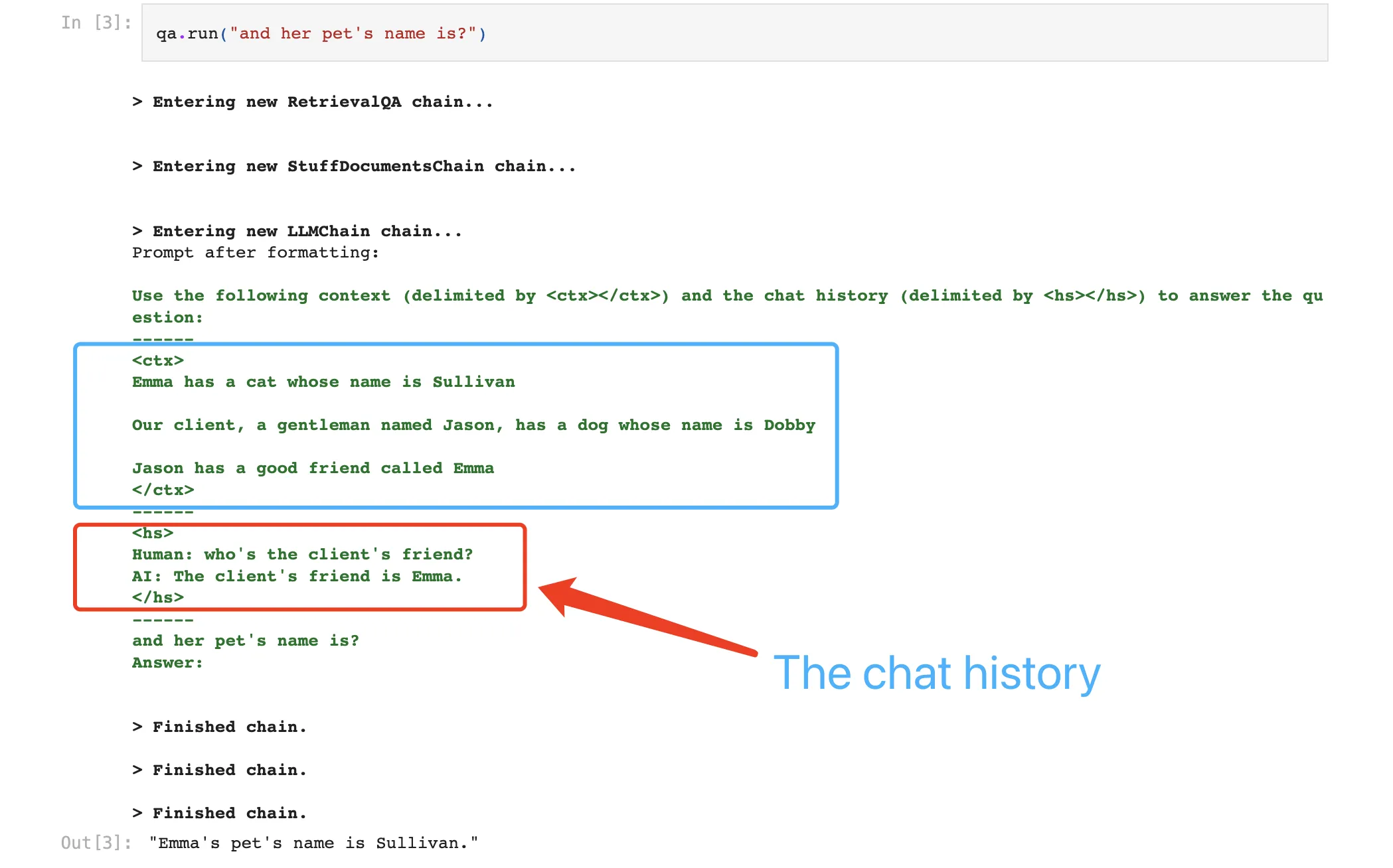
verbose=True记录的信息,我可以看到聊天记录已经被添加到了qa.combine_documents_chain.memory中。所以回答您的问题,是的,这不仅仅是回答单个问题,而且能够理解对话。我已经添加了一个 GitHub Jupyter 笔记本的截图供您参考。 - Shum