我正在寻找一种算法来优化DAG上的评估顺序,以使用最少的内存。可能有点难以解释,所以我会举个例子来说明我的意思。考虑一个具有多个根节点的DAG,它表示某种依赖关系的评估顺序。因此,每个子节点只能在其父节点执行后执行其操作。另外,我们可以从内存中释放不再需要的每个节点。任务是找到最优的顺序评估时间表,以在任何时候使用最少的内存。例如,考虑下面的图:
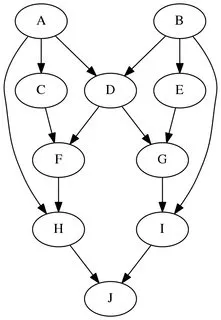
还有两个时间表:
load A - 1 node in memory
load B - 2
eval C - 3
eval D - 4
eval F - 5
unload C - 4
eval H - 5
unload A,F - 3
eval E - 4
eval G - 5
unload D,E - 3
eval I - 4
unload B,G - 2
eval J - 3
unload H,I
Maximum memory trace - 5
而这一个:
load A - 1 node in memory
load B - 2
eval C - 3
eval D - 4
eval E - 5
eval F - 6
unload C - 5
eval G - 6
unload D,E - 4
eval H - 5
unload A,F - 3
eval I - 4
unload B,G - 2
eval J - 3
unload H,I - 1
unload C - 4
eval H - 5
unload A,F - 3
eval E - 4
eval G - 5
unload D,E - 3
eval I - 4
unload B,G - 2
eval J - 3
unload H,I
Maximum memory trace - 6
PS:
仅为澄清,正如@Evgeny Kluev在评论中所指出的那样,这非常类似于寄存器分配,可以使用启发式贪婪的图形着色算法有效地解决。然而,寄存器分配是一个更简单的问题,因为它假定您知道计算顺序,因此可以计算每个变量的生命周期。然后您可以轻松地构建推理图并进行图形着色。在我们的情况下,我们希望实现这一点,同时优化计算顺序。当然,这需要一些假设,例如我们没有指针,并且只有基本数据结构(这就是我的节点代表的东西)。显然,由于图形着色是NP完全的,因此此问题至少是NP完全的。我正在寻找一种某种贪心/启发式算法,在一些不太退化的情况下提供一个良好的解决方案。