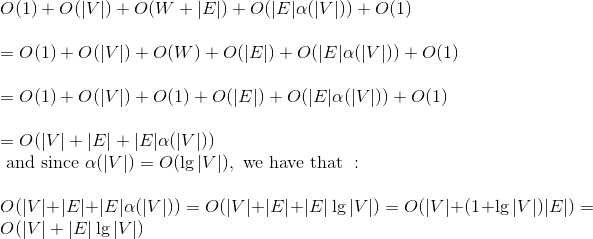Kruskal算法的步骤如下:
根据我的教材:
在第1行初始化集合A需要O(1)时间,在第4行对边进行排序的时间为O(E lgE)。第5-8行的循环在不相交集森林上执行O(E)个FIND-SET和UNION操作。加上|V|个MAKE-SET操作,这些操作总共需要O((V+E)α(V))的时间,其中α是一个非常缓慢增长的函数。因为我们假设G是连通的,所以有|E| <= |V|-1,因此不相交集操作需要O(E α(V))的时间。此外,由于α(V)=O(lgV)=O(lgE),Kruskal算法的总运行时间为O(E lgE)。观察到|E| < |V|^2,因此lg |E|=O(lgV),因此我们可以将Kruskal算法的运行时间重新表述为O(E lgV)。
你能解释一下为什么我们得出的结论是线4中对边进行排序的时间复杂度为O(E lgE)吗?另外,我们如何得出总时间复杂度为O((V+E)α(V))?
此外,假设图中所有边的权重都是从1到|V|的整数。你能让Kruskal算法运行得更快吗?如果边的权重是范围从1到某个常数W的整数,会怎样?时间复杂度如何取决于边的权重?
编辑:
此外,假设图中所有边的权重都是从1到|V|的整数。你能让Kruskal算法运行得更快吗?我想到了以下方法:
为了使Kruskal算法运行更快,我们可以使用计数排序对边进行排序。
- 第1行需要O(1)时间。 - 第2-3行需要O(v)时间。 - 第4行需要O(|V|+|E|)时间。 - 第5-8行需要O(|E|α(|V|))时间。 - 第9行需要O(1)时间。
因此,如果我们使用计数排序来解决边,Kruskal的时间复杂度将为
O(E + V log V)
请问我的想法是否正确?
另外:
如果边的权重是范围从1到某个常数W的整数,会怎样?
我们将再次使用计数排序。算法将保持不变。我们按以下方式找到时间复杂度:
MST-KRUSKAL(G,w)
1. A={}
2. for each vertex v∈ G.V
3. MAKE-SET(v)
4. sort the edges of G.E into nondecreasing order by weight w
5. for each edge (u,v) ∈ G.E, taken in nondecreasing order by weight w
6. if FIND-SET(u)!=FIND-SET(v)
7. A=A U {(u,v)}
8. Union(u,v)
9. return A
根据我的教材:
在第1行初始化集合A需要O(1)时间,在第4行对边进行排序的时间为O(E lgE)。第5-8行的循环在不相交集森林上执行O(E)个FIND-SET和UNION操作。加上|V|个MAKE-SET操作,这些操作总共需要O((V+E)α(V))的时间,其中α是一个非常缓慢增长的函数。因为我们假设G是连通的,所以有|E| <= |V|-1,因此不相交集操作需要O(E α(V))的时间。此外,由于α(V)=O(lgV)=O(lgE),Kruskal算法的总运行时间为O(E lgE)。观察到|E| < |V|^2,因此lg |E|=O(lgV),因此我们可以将Kruskal算法的运行时间重新表述为O(E lgV)。
你能解释一下为什么我们得出的结论是线4中对边进行排序的时间复杂度为O(E lgE)吗?另外,我们如何得出总时间复杂度为O((V+E)α(V))?
此外,假设图中所有边的权重都是从1到|V|的整数。你能让Kruskal算法运行得更快吗?如果边的权重是范围从1到某个常数W的整数,会怎样?时间复杂度如何取决于边的权重?
编辑:
此外,假设图中所有边的权重都是从1到|V|的整数。你能让Kruskal算法运行得更快吗?我想到了以下方法:
为了使Kruskal算法运行更快,我们可以使用计数排序对边进行排序。
- 第1行需要O(1)时间。 - 第2-3行需要O(v)时间。 - 第4行需要O(|V|+|E|)时间。 - 第5-8行需要O(|E|α(|V|))时间。 - 第9行需要O(1)时间。
因此,如果我们使用计数排序来解决边,Kruskal的时间复杂度将为
O(E + V log V)
请问我的想法是否正确?
另外:
如果边的权重是范围从1到某个常数W的整数,会怎样?
我们将再次使用计数排序。算法将保持不变。我们按以下方式找到时间复杂度:
- 第一行需要O(1)时间。
- 第二至三行需要O(|V|)时间。
- 第四行需要O(W+|E|)=O(W)+O(|E|)=O(1)+O(|E|)=O(|E|)时间。
- 第五至八行需要O(|E|α(|V|))时间。
- 第九行需要O(1)时间。
因此时间复杂度为: