我正在尝试使用自定义评分器训练一个RandomForestClassifier,其输出需要取决于其中一个特征。
X数据集包含18个特征: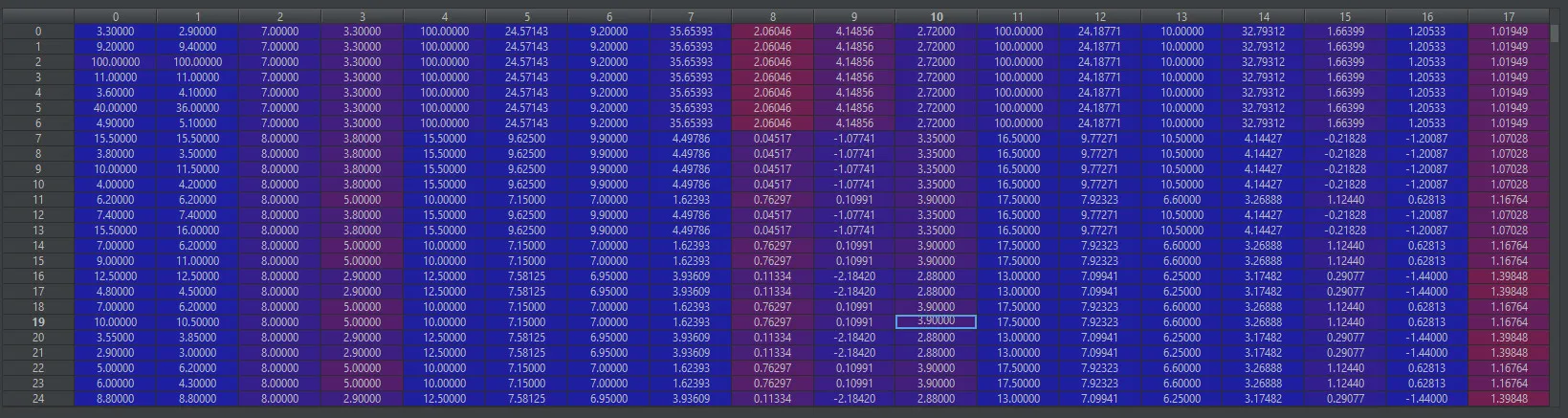 y是通常的0和1数组:
y是通常的0和1数组: RandomForestClassifier与自定义评分器在GridSearchCV实例中使用:
GridSearchCV(classifier, param_grid=[...], scoring=custom_scorer).
RandomForestClassifier与自定义评分器在GridSearchCV实例中使用:
GridSearchCV(classifier, param_grid=[...], scoring=custom_scorer).
通过Scikit-learn函数make_scorer定义自定义评分器: custom_scorer = make_scorer(custom_scorer_function, greater_is_better=True).
如果custom_scorer_function仅依赖于y_true和y_pred,则该框架非常直观。但在我的情况下,我需要定义一个得分器,它使用X数据集中的18个特征之一,即根据y_pred和y_true的值,定制分数将是它们和该特征的组合。
我的问题是,如何将特征传递到custom_scorer_function中,考虑到它的标准签名只接受y_true和y_pred?
我知道它接受额外的**kwargs,但是以这种方式传递整个特征数组并不能解决问题,因为对于每个y_true和y_pred值对,都会调用此函数(需要提取与它们相对应的单个特征值才能使其正常工作,我不确定是否可以完成)。
我尝试增强y_true数组,将该特征打包到其中,并在custom_scorer_function中解包它(第一列是实际标签,第二列是需要计算定制分数的特征值):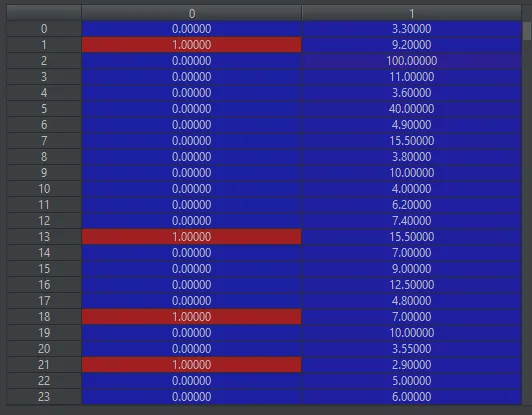 。但这样做违反了分类器对1D标签数组的要求,并触发了以下错误:ValueError: Unknown label type: 'continuous-multioutput'。非常感谢您的任何帮助。谢谢。
。但这样做违反了分类器对1D标签数组的要求,并触发了以下错误:ValueError: Unknown label type: 'continuous-multioutput'。非常感谢您的任何帮助。谢谢。
X数据集包含18个特征:
y是通常的0和1数组:
RandomForestClassifier与自定义评分器在GridSearchCV实例中使用:
GridSearchCV(classifier, param_grid=[...], scoring=custom_scorer).通过Scikit-learn函数make_scorer定义自定义评分器: custom_scorer = make_scorer(custom_scorer_function, greater_is_better=True).
如果custom_scorer_function仅依赖于y_true和y_pred,则该框架非常直观。但在我的情况下,我需要定义一个得分器,它使用X数据集中的18个特征之一,即根据y_pred和y_true的值,定制分数将是它们和该特征的组合。
我的问题是,如何将特征传递到custom_scorer_function中,考虑到它的标准签名只接受y_true和y_pred?
我知道它接受额外的**kwargs,但是以这种方式传递整个特征数组并不能解决问题,因为对于每个y_true和y_pred值对,都会调用此函数(需要提取与它们相对应的单个特征值才能使其正常工作,我不确定是否可以完成)。
我尝试增强y_true数组,将该特征打包到其中,并在custom_scorer_function中解包它(第一列是实际标签,第二列是需要计算定制分数的特征值):
。但这样做违反了分类器对1D标签数组的要求,并触发了以下错误:ValueError: Unknown label type: 'continuous-multioutput'。非常感谢您的任何帮助。谢谢。