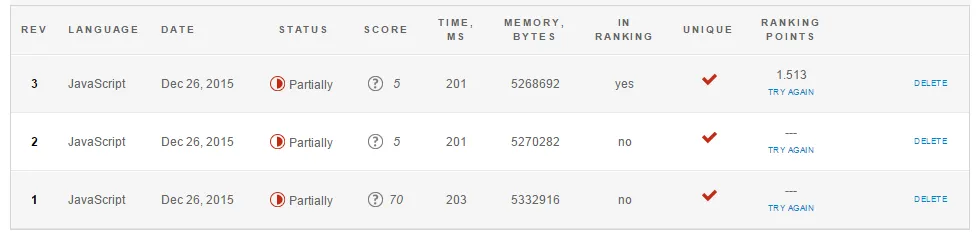
我已经通过不同的方式解决了CodeEval上一个简单的问题,其规范可以在这里找到(只有几行)。
我已经制作了3个工作版本(其中一个是Scala),但我不明白为什么我的最新Java版本在时间和内存方面表现不如预期。
我还将其与在Github上找到的代码进行了比较。以下是CodeEval返回的性能统计信息:
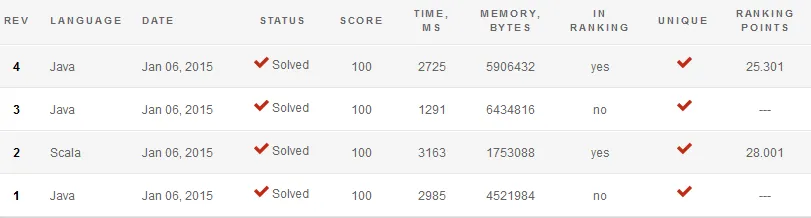
版本1是在Github上找到的版本。版本2是我的Scala解决方案:
object Main extends App {
val p = Pattern.compile("\\d+")
scala.io.Source.fromFile(args(0)).getLines
.filter(!_.isEmpty)
.map(line => {
val dists = new TreeSet[Int]
val m = p.matcher(line)
while (m.find) dists += m.group.toInt
val list = dists.toList
list.zip(0 +: list).map { case (x,y) => x - y }.mkString(",")
})
.foreach(println)
}
版本3是我的Java解决方案,我认为它是最好的:
public class Main {
public static void main(String[] args) throws IOException {
Pattern p = Pattern.compile("\\d+");
File file = new File(args[0]);
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
while ((line = br.readLine()) != null) {
Set<Integer> dists = new TreeSet<Integer>();
Matcher m = p.matcher(line);
while (m.find()) dists.add(Integer.parseInt(m.group()));
Iterator<Integer> it = dists.iterator();
int prev = 0;
StringBuilder sb = new StringBuilder();
while (it.hasNext()) {
int curr = it.next();
sb.append(curr - prev);
sb.append(it.hasNext() ? "," : "");
prev = curr;
}
System.out.println(sb);
}
br.close();
}
}
- 版本4与版本3相同,只是我不使用
StringBuilder来打印输出,并像版本1一样执行
这是我对这些结果的解释:
版本1由于
System.out.print调用次数过多而速度太慢。此外,在非常大的行上使用split(在执行的测试中就是这种情况)会占用大量内存。版本2似乎也很慢,但主要是因为在CodeEval上运行Scala代码的“开销”,即使非常高效的代码也会运行缓慢。
版本2使用不必要的内存来从集合构建列表,这也需要一些时间,但应该不会太重要。编写更高效的Scala可能像编写Java一样,所以我更喜欢优雅而不是性能。
版本3在我看来不应该使用那么多内存。使用
StringBuilder对内存的影响与在版本2中调用mkString相同。版本4证明了对
System.out.println的调用正在减慢程序的速度。
有人能解释这些结果吗?