我一直在尝试对使用 cobra 构建的 cli 工具进行堆使用情况分析。
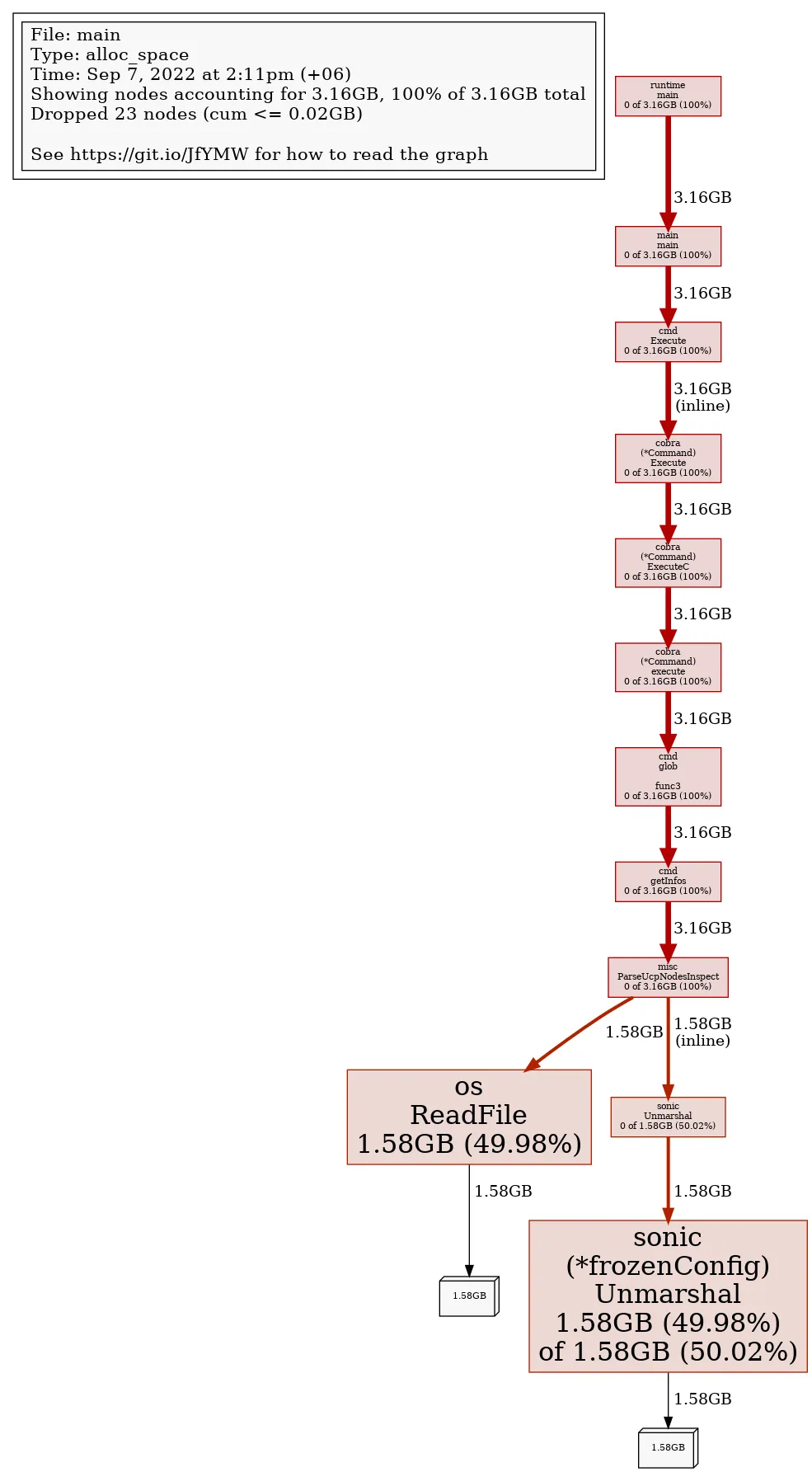
pprof 工具显示如下:
Flat Flat% Sum% Cum Cum% Name Inlined?
1.58GB 49.98% 49.98% 1.58GB 49.98% os.ReadFile
1.58GB 49.98% 99.95% 1.58GB 50.02% github.com/bytedance/sonic.(*frozenConfig).Unmarshal
0 0.00% 99.95% 3.16GB 100.00% runtime.main
0 0.00% 99.95% 3.16GB 100.00% main.main
0 0.00% 99.95% 3.16GB 100.00% github.com/spf13/cobra.(*Command).execute
0 0.00% 99.95% 3.16GB 100.00% github.com/spf13/cobra.(*Command).ExecuteC
0 0.00% 99.95% 3.16GB 100.00% github.com/spf13/cobra.(*Command).Execute (inline)
0 0.00% 99.95% 3.16GB 100.00% github.com/mirantis/broker/misc.ParseUcpNodesInspect
0 0.00% 99.95% 3.16GB 100.00% github.com/mirantis/broker/cmd.glob..func3
0 0.00% 99.95% 3.16GB 100.00% github.com/mirantis/broker/cmd.getInfos
0 0.00% 99.95% 3.16GB 100.00% github.com/mirantis/broker/cmd.Execute
0 0.00% 99.95% 1.58GB 50.02% github.com/bytedance/sonic.Unmarshal
但是ps在最后阶段几乎消耗了6752.23 Mb(rss)。
此外,我将defer profile.Start(profile.MemProfileHeap).Stop()放在最后一个执行的函数中。将分析器放入func main中不会显示任何内容。因此,我跟踪了这些函数,并发现最后一个函数使用了相当多的内存。
我的问题是,如何找到缺失的约3GB内存?