当我将.wav文件中的数据存储到字节数组中时,这些值代表什么意思? 我读到它们是以两个字节表示的,但这两个字节的确切含义是什么?
6个回答
76
你一定听说过,音频信号是由某种波形表示的。如果你曾看过这种线条上下波动的波形图——那基本上就是那些文件里面的东西。看看来自http://en.wikipedia.org/wiki/Sampling_rate的文件图片。
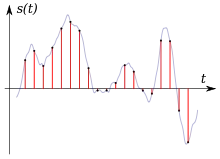 你可以看到音频波形(灰色线)。该波形的当前值会被反复测量并表示为一个数字。这就是那些字节中的数字。有两个不同的调整可以用来控制它:每秒采取的测量次数(称为采样率,以赫兹为单位——即你每秒获取多少个样本)以及你进行精确度测量的方式。在2字节的情况下,你需要为一个测量采取两个字节(通常是从-32768到32767之间的值)。因此,通过给出的数字,你可以重新创建原始波形(当然,这仅限于一定程度的质量,但在数字存储时总是如此)。而重新创建原始波形正是你的扬声器在播放时尝试做的事情。
你可以看到音频波形(灰色线)。该波形的当前值会被反复测量并表示为一个数字。这就是那些字节中的数字。有两个不同的调整可以用来控制它:每秒采取的测量次数(称为采样率,以赫兹为单位——即你每秒获取多少个样本)以及你进行精确度测量的方式。在2字节的情况下,你需要为一个测量采取两个字节(通常是从-32768到32767之间的值)。因此,通过给出的数字,你可以重新创建原始波形(当然,这仅限于一定程度的质量,但在数字存储时总是如此)。而重新创建原始波形正是你的扬声器在播放时尝试做的事情。
还有一些你需要知道的细节。首先,由于它是两个字节,你需要知道字节顺序(大端,小端)以正确地重新创建数字。其次,你需要知道有多少个通道以及它们是如何存储的。通常你会有单声道(一个通道)或立体声(两个通道),但更多也是可能的。如果你有多于一个通道,你需要知道他们是如何存储的。通常情况下,它们会交叉排列,这意味着你会在每个时间点上获取每个通道的一个值,然后在下一个时间点之前获取所有通道的所有值。
为了说明:如果你有两个8字节的通道数据和一个16位数字,请看以下内容:
你可以看到音频波形(灰色线)。该波形的当前值会被反复测量并表示为一个数字。这就是那些字节中的数字。有两个不同的调整可以用来控制它:每秒采取的测量次数(称为采样率,以赫兹为单位——即你每秒获取多少个样本)以及你进行精确度测量的方式。在2字节的情况下,你需要为一个测量采取两个字节(通常是从-32768到32767之间的值)。因此,通过给出的数字,你可以重新创建原始波形(当然,这仅限于一定程度的质量,但在数字存储时总是如此)。而重新创建原始波形正是你的扬声器在播放时尝试做的事情。还有一些你需要知道的细节。首先,由于它是两个字节,你需要知道字节顺序(大端,小端)以正确地重新创建数字。其次,你需要知道有多少个通道以及它们是如何存储的。通常你会有单声道(一个通道)或立体声(两个通道),但更多也是可能的。如果你有多于一个通道,你需要知道他们是如何存储的。通常情况下,它们会交叉排列,这意味着你会在每个时间点上获取每个通道的一个值,然后在下一个时间点之前获取所有通道的所有值。
为了说明:如果你有两个8字节的通道数据和一个16位数字,请看以下内容:
abcdefgh
a和b组成了第一个16位数字,是第1声道的第一个值;c和d则是第2声道的第一个值。e和f是第1声道的第二个值,g和h是第2声道的第二个值。因为这不足以构成一秒钟的数据,所以你听不到太多东西。
将所有这些信息结合起来,可以计算出您拥有的比特率,也就是录音机每秒生成的信息位数。在我们的示例中,每个采样每个声道会产生2个字节。如果有两个声道,那么就是4个字节。您需要大约44000个每秒的样本来表示人类正常听到的声音。因此,您将得到每秒176000个字节,即1408000个比特。
当然,这里不是2位值,而是两个2字节的值,否则您会得到非常糟糕的质量。
- kratenko
6
7你最后没有提到那张图中垂直轴代表什么,或者保存的值的性质是什么。 - wmac
谢谢您的回答,但我有一个疑问:如果我有9745238帧和2个通道的音频,那么我将同时获得第1和第2通道的数据,而不是像您的示例“abcdefgh”中那样交替。然后a将属于第1个值到通道1,b将属于通道2的第1个值,依此类推。难道不应该是这样吗? - P.hunter
在这个例子中,每个值都由2个字节(=16位)组成,因此
ab只是一个单独的值,它被存储为“signed int16”。cd是第二个通道的第一个值。对于8位音频,您的版本是正确的(我的示例与我在https://de.wikipedia.org/wiki/RIFF_WAVE#%E2%80%9EData%E2%80%9C-Abschnitt上阅读的德语维基百科文章一致)。 - kratenko哦,好的,实际上我有这个疑问是因为当我观察一个具有2个通道的音频文件时,在两个Python模块
wave和scipy下,wav返回了一个字节字符串,我后来将其转换为16位int,但是scipy返回了一个9745238 X 2的带符号16位int矩阵(其中1列是通道1数据,2列是通道2数据),当我将其与nparray的wav输出进行比较时,它的顺序与我在先前评论中告诉你的顺序相反,所以它与你的答案有些矛盾。 - P.hunter然而,是否有任何强大的方法可以每秒或毫秒找到这些值(连续的1、2通道),因为当我将帧速率乘以我的音频文件的持续时间时,它必须返回我总帧数/样本数,但不是这样。它返回了“9702000”,而实际上总共有“9745238”个,你有什么猜测为什么会发生这种情况? - P.hunter
@kratenko:你能否来帮助我或在这里评论我的类似问题?https://stackoverflow.com/questions/58730713/how-to-get-volume-level-in-current-sample-delphi-7 关于16位44Khz,我需要解释和评论为什么数据区域中的值与图像曲线不同。 - Johny Bony
21
通常,前44个字节是标准的RIFF头文件,详情请参考:http://tiny.systems/software/soundProgrammer/WavFormatDocs.pdf和http://www.topherlee.com/software/pcm-tut-wavformat.html
苹果/OSX/macOS/iOS创建的.wav文件可能会在头文件中添加'FLLR'填充块,因此将初始RIFF头的大小从44个字节增加到4k个字节(也许为了更好地对齐原始采样数据的磁盘或存储块)。
剩下的内容往往是以16位线性PCM格式表示的有符号2's补码小端格式,以44100 Hz的速率表示任意缩放的样本。

- hotpaw2
2
1你能告诉我如何播放没有任何头部的波形字节流吗? - Babu James
@hotpaw2:请问您能否前来帮助我或者在这里评论一下我的类似问题?https://stackoverflow.com/questions/58730713/how-to-get-volume-level-in-current-sample-delphi-7 关于16位44Khz,我需要解释和评论为什么数据区域中的值与图像曲线不同。 - Johny Bony
15
WAVE (.wav) 文件包含一个头部,其中包含音频文件数据的格式信息。在头部之后是实际的音频原始数据。您可以在下面检查它们的确切含义。
Positions Typical Value Description
1 - 4 "RIFF" Marks the file as a RIFF multimedia file.
Characters are each 1 byte long.
5 - 8 (integer) The overall file size in bytes (32-bit integer)
minus 8 bytes. Typically, you'd fill this in after
file creation is complete.
9 - 12 "WAVE" RIFF file format header. For our purposes, it
always equals "WAVE".
13-16 "fmt " Format sub-chunk marker. Includes trailing null.
17-20 16 Length of the rest of the format sub-chunk below.
21-22 1 Audio format code, a 2 byte (16 bit) integer.
1 = PCM (pulse code modulation).
23-24 2 Number of channels as a 2 byte (16 bit) integer.
1 = mono, 2 = stereo, etc.
25-28 44100 Sample rate as a 4 byte (32 bit) integer. Common
values are 44100 (CD), 48000 (DAT). Sample rate =
number of samples per second, or Hertz.
29-32 176400 (SampleRate * BitsPerSample * Channels) / 8
This is the Byte rate.
33-34 4 (BitsPerSample * Channels) / 8
1 = 8 bit mono, 2 = 8 bit stereo or 16 bit mono, 4
= 16 bit stereo.
35-36 16 Bits per sample.
37-40 "data" Data sub-chunk header. Marks the beginning of the
raw data section.
41-44 (integer) The number of bytes of the data section below this
point. Also equal to (#ofSamples * #ofChannels *
BitsPerSample) / 8
45+ The raw audio data.
我将所有这些内容从http://www.topherlee.com/software/pcm-tut-wavformat.html复制到这里。
- seanxiaoxiao
1
4请正确使用术语。您混淆了字节和位。32个字节整数并不存在,应该是32位。 - RutledgePaulV
11
正如其他人指出的那样,wav文件中有元数据,但我认为你的问题可能是,具体来说,这些(数据而非元数据)字节代表什么?如果是这样,那么这些字节代表记录的信号值。
那是什么意思呢?如果您提取表示每个采样的两个字节(假设是单声道录制,即只记录了一个声道),则您得到了一个16位值。在WAV中,16位是(始终?)带符号和小端编码(顺序)。因此,如果您将该16位采样的值除以2 ^ 16(或者如果是带符号数据,则除以2 ^ 15),您将得到一个标准化为-1至1范围内的采样。对所有采样执行此操作,并根据时间(时间由录音中每秒有多少个样本决定;例如,44.1KHz意味着每毫秒有44.1个样本,因此第一个样本值将在t = 0处绘制,第44个样本值在t = 1ms处绘制等等)将它们与时间绘制,您就得到了大致代表最初记录内容的信号。
那是什么意思呢?如果您提取表示每个采样的两个字节(假设是单声道录制,即只记录了一个声道),则您得到了一个16位值。在WAV中,16位是(始终?)带符号和小端编码(顺序)。因此,如果您将该16位采样的值除以2 ^ 16(或者如果是带符号数据,则除以2 ^ 15),您将得到一个标准化为-1至1范围内的采样。对所有采样执行此操作,并根据时间(时间由录音中每秒有多少个样本决定;例如,44.1KHz意味着每毫秒有44.1个样本,因此第一个样本值将在t = 0处绘制,第44个样本值在t = 1ms处绘制等等)将它们与时间绘制,您就得到了大致代表最初记录内容的信号。
- Pat
1
两个通道应该怎么办? - Danon
7
我猜你的问题是“ .wav 文件数据块中的字节代表什么?” 让我们系统地了解一下。
前奏: 假设我们使用某个设备播放 5KHz 正弦波,并在单声道(mono)上进行录制,录制后保存在名为 'sine.wav' 的文件中,你已经知道该文件头所代表的内容。 让我们来看一些重要的定义:
前奏: 假设我们使用某个设备播放 5KHz 正弦波,并在单声道(mono)上进行录制,录制后保存在名为 'sine.wav' 的文件中,你已经知道该文件头所代表的内容。 让我们来看一些重要的定义:
- 样本: 任何信号的样本表示在取样点上信号的幅度。
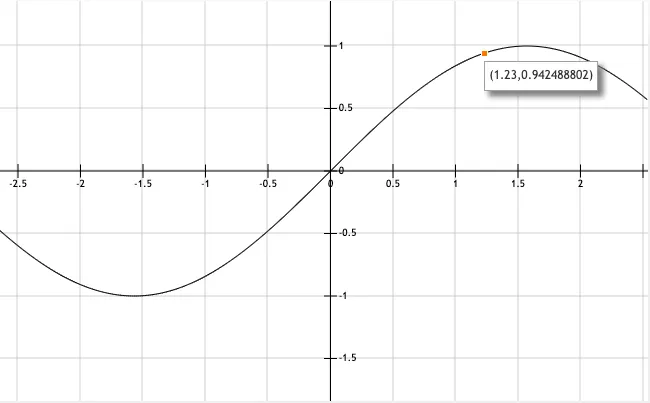
- 采样率: 可以在一个给定的时间间隔内取许多这样的样本。假设我们在 1 秒钟内对我们的正弦波进行 10 次采样。每个样本间隔为 0.1 秒。因此我们每秒有 10 个样本,采样率为 10Hz。头部的第25到28个字节表示采样率。
现在来回答你的问题:
实际上不可能将整个正弦波写入文件,因为正弦波有无限多的点。相反,我们会固定一个采样率并在这些间隔中开始对波进行采样并记录幅度。(所选取的采样频率是为了使用我们即将采取的样本最小化失真地重建信号。由于样本数量不足导致的重建信号失真称为'aliasing'。)
为避免混叠,采样率被选择为 两倍于正弦波的频率(5kHz)以上 (这被称为 '采样定理',两倍于频率的速率称为 '奈奎斯特速率')。 因此我们决定采用 12kHz 的采样率,这意味着我们将在一秒钟内对我们的正弦波进行 12000 次采样。
一旦我们开始录制,如果我们记录的信号是 5kHz 频率的正弦波,我们将拥有 12000 * 5 个样本(值)。 我们将这些 60000 个值放入一个数组中。 然后我们创建适当的头部来反映我们的元数据,然后将这些样本从十进制转换为它们的十六进制等价值。 这些值随后写入我们的 .wav 文件的数据字节中。
绘制图表使用: http://fooplot.com
- Sushrut Kasture
1
请问您能否前来帮助我或在这里评论我的类似问题?https://stackoverflow.com/questions/58730713/how-to-get-volume-level-in-current-sample-delphi-7 关于16位44Khz,我需要解释和评论为什么数据区域中的值与图像曲线不同。 - Johny Bony
3
两位音频听起来可能不是很好听 :) 在大多数情况下,它们将采样值表示为16位有符号数字,这些数字代表以44.1kHz等频率采样的音频波形。
- TJD
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接