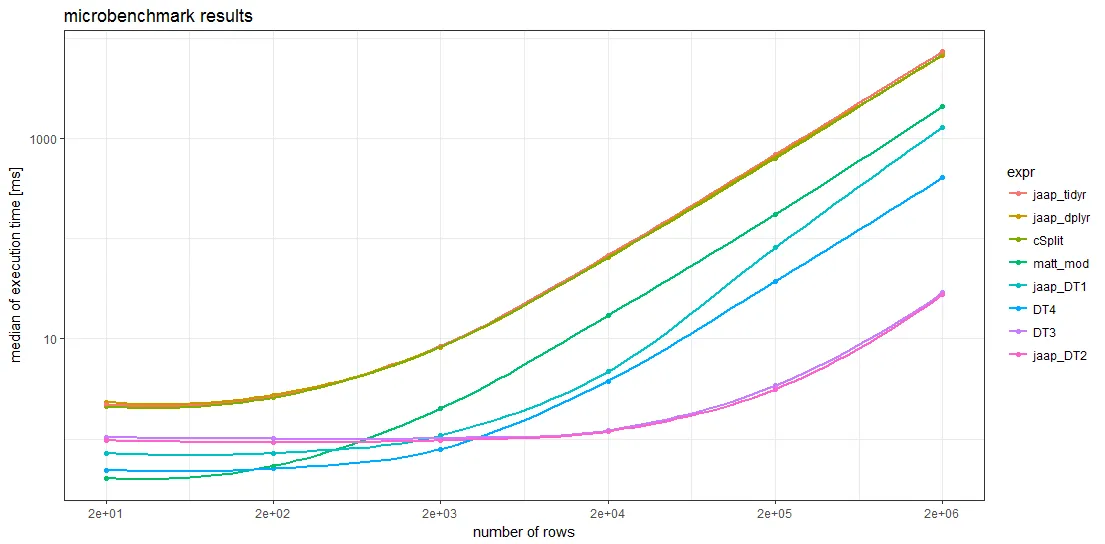
另一个基准测试使用来自
base的
strsplit得出结果,目前可以推荐用它来将列中的逗号分隔字符串拆分成单独的行,因为在各种规模下它是最快的:
s <- strsplit(v$director, ",", fixed=TRUE)
s <- data.frame(director=unlist(s), AB=rep(v$AB, lengths(s)))
请注意,使用
fixed=TRUE会对时间产生重大影响。
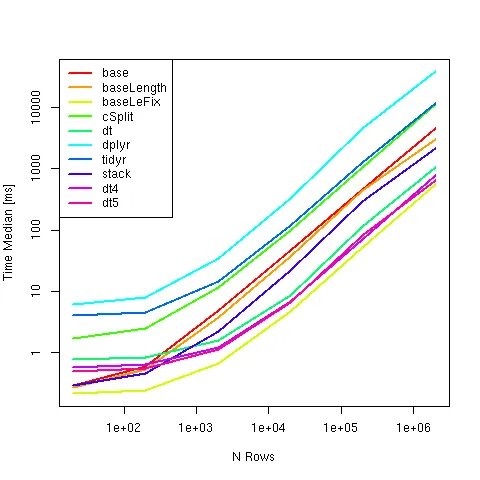
对比方法:
met <- alist(base = {s <- strsplit(v$director, ",")
s <- data.frame(director=unlist(s), AB=rep(v$AB, sapply(s, FUN=length)))}
, baseLength = {s <- strsplit(v$director, ",")
s <- data.frame(director=unlist(s), AB=rep(v$AB, lengths(s)))}
, baseLeFix = {s <- strsplit(v$director, ",", fixed=TRUE)
s <- data.frame(director=unlist(s), AB=rep(v$AB, lengths(s)))}
, cSplit = s <- cSplit(v, "director", ",", direction = "long")
, dt = s <- setDT(v)[, lapply(.SD, function(x) unlist(tstrsplit(x, ","
, fixed=TRUE))), by = AB][!is.na(director)]
, dplyr = {s <- v %>%
mutate(director = strsplit(director, ",", fixed=TRUE)) %>%
unnest(director)}
, tidyr = s <- separate_rows(v, director, sep = ",")
, stack = s <- stack(setNames(strsplit(v$director, ",", fixed=TRUE), v$AB))
, dt4 = {s <- setDT(v)[, .(director = unlist(strsplit(director, ","
, fixed = TRUE))), by = .(AB)]}
, dt5 = {s <- vT[, .(director = unlist(strsplit(director, ","
, fixed = TRUE))), by = .(AB)]}
)
图书馆:
library(microbenchmark)
library(splitstackshape)
library(data.table)
library(dplyr)
library(tidyr)
数据:
v0 <- data.frame(director = c("Aaron Blaise,Bob Walker", "Akira Kurosawa",
"Alan J. Pakula", "Alan Parker", "Alejandro Amenabar", "Alejandro Gonzalez Inarritu",
"Alejandro Gonzalez Inarritu,Benicio Del Toro", "Alejandro González Iñárritu",
"Alex Proyas", "Alexander Hall", "Alfonso Cuaron", "Alfred Hitchcock",
"Anatole Litvak", "Andrew Adamson,Marilyn Fox", "Andrew Dominik",
"Andrew Stanton", "Andrew Stanton,Lee Unkrich", "Angelina Jolie,John Stevenson",
"Anne Fontaine", "Anthony Harvey"), AB = c('A', 'B', 'A', 'A', 'B', 'B', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'A'))
计算和定时结果:
n <- 10^(0:5)
x <- lapply(n, function(n) {v <- v0[rep(seq_len(nrow(v0)), n),]
vT <- setDT(v)
ti <- min(100, max(3, 1e4/n))
microbenchmark(list = met, times = ti, control=list(order="block"))})
y <- do.call(cbind, lapply(x, function(y) aggregate(time ~ expr, y, median)))
y <- cbind(y[1], y[-1][c(TRUE, FALSE)])
y[-1] <- y[-1] / 1e6
names(y)[-1] <- paste("n:", n * nrow(v0))
y
注意,像这样的方法
(v <- rbind(v0[1:2,], v0[1,]))
setDT(v)[, strsplit(director, ","
, fixed=TRUE), by = .(AB, director)][,.(director = V1, AB)]
返回一个针对唯一的“导演”进行
strsplit 的结果,并可能可比较。
tmp <- unique(v)
s <- strsplit(tmp$director, ",", fixed=TRUE)
s <- data.frame(director=unlist(s), AB=rep(tmp$AB, lengths(s)))
但据我理解,这并没有被要求。