我有6张表:
CREATE TABLE IF NOT EXISTS `sbpr_groups` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`active` tinyint(1) DEFAULT '0',
`dnd` tinyint(1) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=32 ;
CREATE TABLE IF NOT EXISTS `sbpr_newsletter` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`created_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`from` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`mail` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`subject` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`body` text COLLATE utf8_unicode_ci,
`attach1` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`attach2` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`attach3` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci AUTO_INCREMENT=14;
CREATE TABLE IF NOT EXISTS `sbpr_news_groups` (
`newsletter_id` int(11) NOT NULL,
`groups` int(11) NOT NULL,
KEY `fk_sbpr_news_groups_sbpr_newsletter1` (`newsletter_id`),
KEY `fk_sbpr_news_groups_sbpr_groups1` (`groups`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
CREATE TABLE IF NOT EXISTS `sbpr_news_recs` (
`newsletter_id` int(11) NOT NULL,
`recipients` int(11) NOT NULL,
KEY `fk_sbpr_news_recs_sbpr_newsletter1` (`newsletter_id`),
KEY `fk_sbpr_news_recs_sbpr_recipients1` (`recipients`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
CREATE TABLE IF NOT EXISTS `sbpr_recipients` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`mail` varchar(160) DEFAULT NULL,
`date_reg` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`active` tinyint(1) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=3008 ;
CREATE TABLE IF NOT EXISTS `sbpr_rec_groups` (
`rec_id` int(11) NOT NULL,
`group` int(11) NOT NULL,
KEY `fk_sbpr_rec_groups_sbpr_recipients` (`rec_id`),
KEY `fk_sbpr_rec_groups_sbpr_groups1` (`group`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
使用这些外键:
ALTER TABLE `sbpr_news_groups`
ADD CONSTRAINT `fk_sbpr_news_groups_sbpr_groups1`
FOREIGN KEY (`groups`) REFERENCES `sbpr_groups` (`id`)
ON DELETE CASCADE ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_sbpr_news_groups_sbpr_newsletter1`
FOREIGN KEY (`newsletter_id`) REFERENCES `sbpr_newsletter` (`id`)
ON DELETE CASCADE ON UPDATE NO ACTION;
ALTER TABLE `sbpr_news_recs`
ADD CONSTRAINT `fk_sbpr_news_recs_sbpr_newsletter1`
FOREIGN KEY (`newsletter_id`) REFERENCES `sbpr_newsletter` (`id`)
ON DELETE CASCADE ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_sbpr_news_recs_sbpr_recipients1`
FOREIGN KEY (`recipients`) REFERENCES `sbpr_recipients` (`id`)
ON DELETE CASCADE ON UPDATE NO ACTION;
ALTER TABLE `sbpr_rec_groups`
ADD CONSTRAINT `fk_sbpr_rec_groups_sbpr_groups1`
FOREIGN KEY (`group`) REFERENCES `sbpr_groups` (`id`)
ON DELETE CASCADE ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_sbpr_rec_groups_sbpr_recipients`
FOREIGN KEY (`rec_id`) REFERENCES `sbpr_recipients` (`id`)
ON DELETE CASCADE ON UPDATE NO ACTION;
表格的可视化结构:
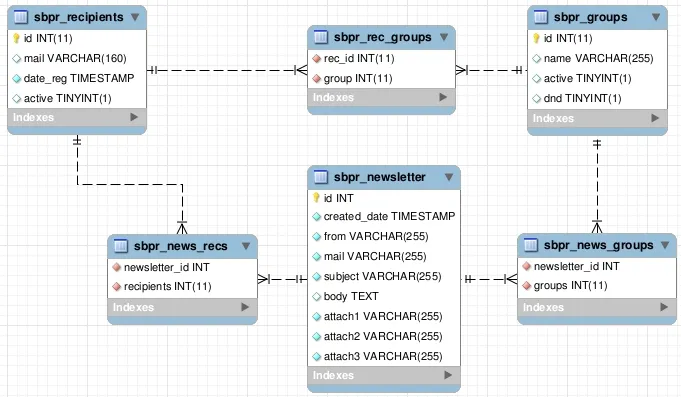
我想从sbpr_newsletter表中选择所有行,并为每行添加从sbpr_recipients表中的行数,这些行数的ID要么在sbpr_news_recs中指定,要么在sbpr_rec_groups中指定,具体取决于外键。
例如,我想选择当前新闻通讯的所有收件人数量,这些收件人要么在sbpr_news_recs中,要么存在于sbpr_rec_groups中的组中,再加上活跃接收者的数量。
我有可用的SQL:
SELECT d.id, d.subject , d.created_date,
(SELECT count(*) FROM sbpr_recipients r
LEFT JOIN sbpr_news_recs nr ON nr.recipients = r.id
LEFT JOIN sbpr_rec_groups g ON g.rec_id = r.id
LEFT JOIN sbpr_news_groups ng ON ng.groups = g.group
WHERE nr.newsletter_id = d.id OR ng.newsletter_id = d.id) AS repicients,
(SELECT count(*) FROM sbpr_recipients r
LEFT JOIN sbpr_news_recs nr ON nr.recipients = r.id
LEFT JOIN sbpr_rec_groups g ON g.rec_id = r.id
LEFT JOIN sbpr_news_groups ng ON ng.groups = g.group
WHERE (nr.newsletter_id = d.id OR ng.newsletter_id = d.id)
AND r.active = 1) AS active_repicients
FROM sbpr_newsletter d
ORDER BY d.id ASC, d.id
这个 SQL 查询的解释:
问题: 如何优化我的 SQL 查询?
order by d.id ASC, d.id更改为order by d.id ASC时,您的解释会是什么样子? - eisbergEXPLAIN EXTENDED ...来进行测试。 - eisberg