c++20中的协程是什么?
它与"Parallelism2"或/和"Concurrency2"有何不同之处(请查看下面的图片)?
下面的图片来自ISOCPP。
https://isocpp.org/files/img/wg21-timeline-2017-03.png
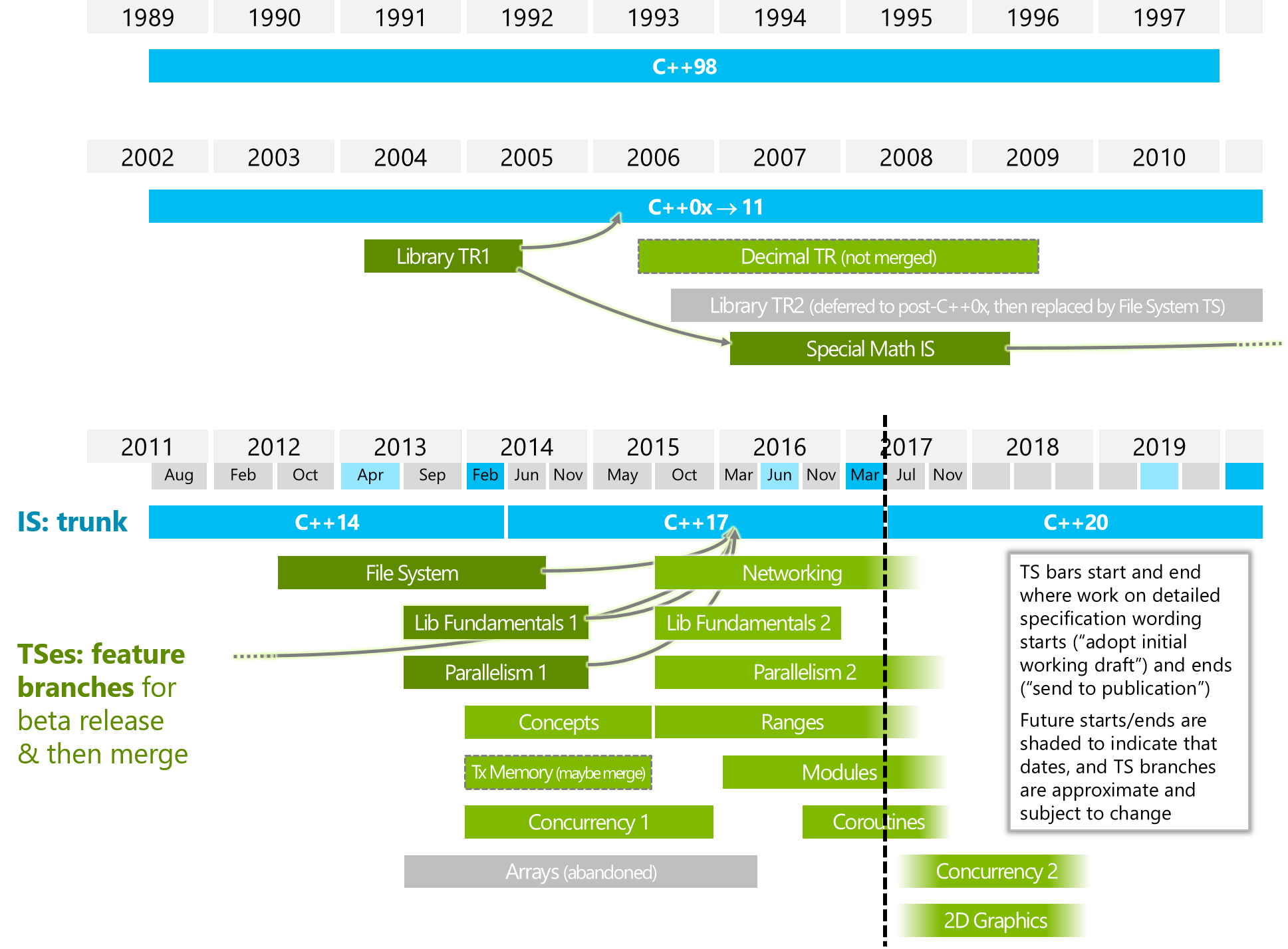{kind=link}
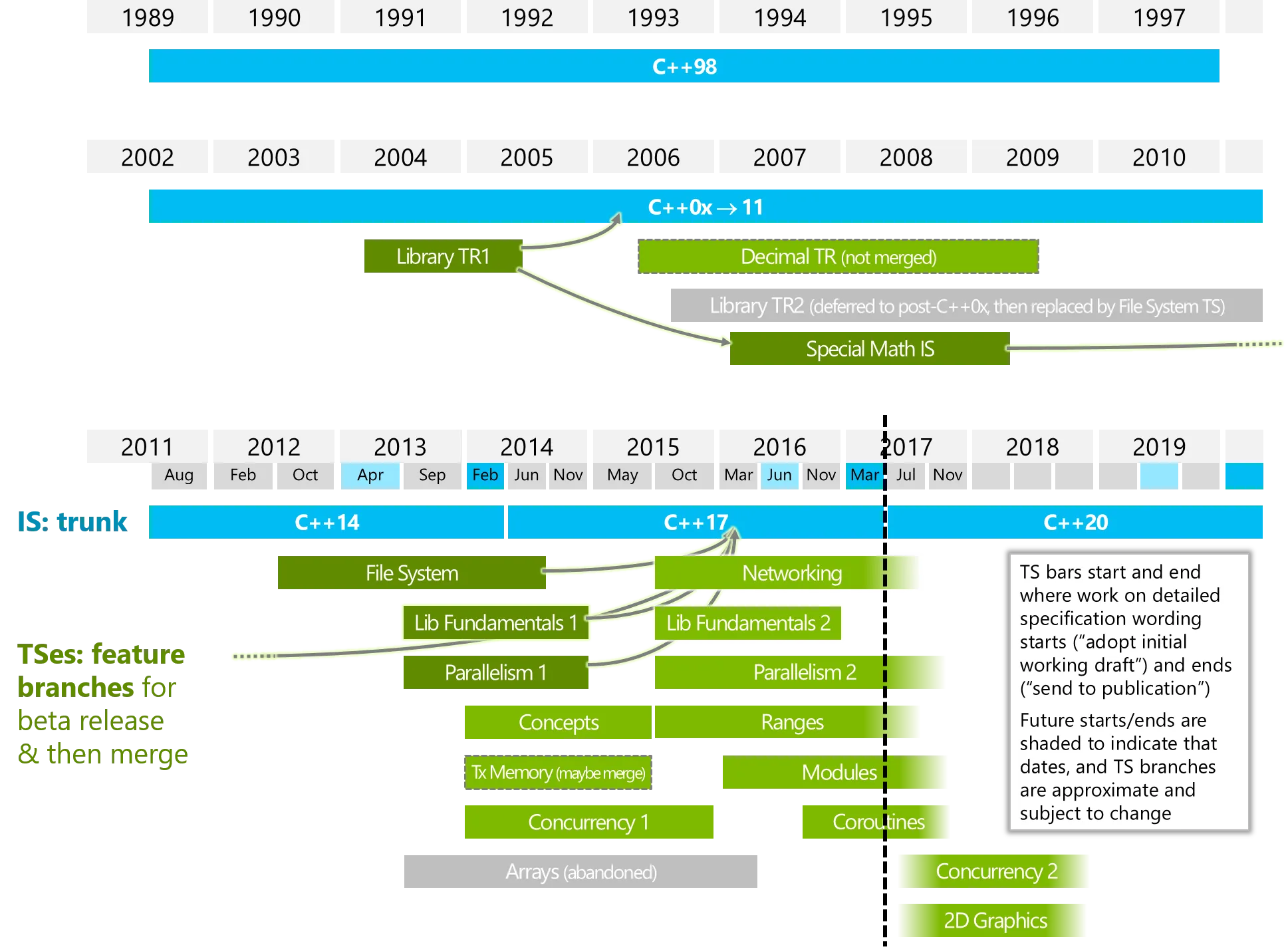
c++20中的协程是什么?
它与"Parallelism2"或/和"Concurrency2"有何不同之处(请查看下面的图片)?
下面的图片来自ISOCPP。
https://isocpp.org/files/img/wg21-timeline-2017-03.png
从抽象的层面来看,协程将执行状态与执行线程的概念分离。
SIMD(单指令多数据)具有多个“执行线程”,但只有一个执行状态(它只处理多个数据)。可以说并行算法有点类似于此,因为您在不同的数据上运行一个“程序”。
线程具有多个“执行线程”和多个执行状态。您有多个程序和多个执行线程。
协程具有多个执行状态,但不拥有执行线程。您有一个程序,程序具有状态,但没有执行线程。
最简单的协程示例是其他语言中的生成器或枚举。
伪代码示例:
function Generator() {
for (i = 0 to 100)
produce i
}
co_return co_await co_yield,以及一些与它们一起工作的库类型。通过在函数体中使用这三个关键字之一,函数成为协程。因此,从它们的声明中无法区分它们是否为函数。在函数体中使用这三个关键字之一时,会进行一些标准规定的返回类型和参数的检查,并将函数转换为协程。这种检查告诉编译器在挂起函数时存储函数状态的位置。最简单的协程是生成器。generator<int> get_integers( int start=0, int step=1 ) {
for (int current=start; true; current+= step)
co_yield current;
}
co_yield暂停函数的执行,将该状态存储在generator<int>中,并通过generator<int>返回current的值。
您可以循环遍历返回的整数。
与此同时,co_await允许您将一个协程插入另一个协程中。如果您在一个协程中并且需要在继续之前等待可等待的事物(通常是一个协程)的结果,则对其进行co_await操作。如果它们已准备好,您会立即继续;如果没有准备好,您将暂停,直到您正在等待的可等待对象准备就绪。
std::future<std::expected<std::string>> load_data( std::string resource )
{
auto handle = co_await open_resouce(resource);
while( auto line = co_await read_line(handle)) {
if (std::optional<std::string> r = parse_data_from_line( line ))
co_return *r;
}
co_return std::unexpected( resource_lacks_data(resource) );
}
load_data是一个协程,当打开命名资源并解析到找到所需数据的点时,会生成一个std::future。
open_resource和read_line可能是异步协程,用于打开文件并从中读取行。 co_await将load_data的暂停和就绪状态连接到它们的进度。
C ++协程比这更灵活,因为它们是在用户空间类型之上实现了一组最小的语言功能。 用户空间类型有效地定义了co_return co_await和co_yield的含义 - 我看到人们使用它来实现单子可选表达式,使得对空可选的co_await自动传播空状态到外部可选项:
modified_optional<int> add( modified_optional<int> a, modified_optional<int> b ) {
co_return (co_await a) + (co_await b);
}
而不是
std::optional<int> add( std::optional<int> a, std::optional<int> b ) {
if (!a) return std::nullopt;
if (!b) return std::nullopt;
return *a + *b;
}
;;。 - Yakk - Adam Nevraumont协程就像一个C函数,它有多个返回语句,并且当第二次调用时不会从函数开始执行,而是从上一次执行的返回后的第一条指令开始执行。这个执行位置与在非协程函数中将存储在堆栈中的所有自动变量一起保存。
微软先前实验性地实现了一个协程版本,它使用了复制的堆栈,所以你甚至可以从深层嵌套的函数中返回。但是这个版本被C++委员会拒绝了。例如,您可以使用Boosts fiber库获取此实现。
协程(coroutines)是指(在C++中)能够“等待”其他程序完成并提供所需内容以使暂停、暂停等待的程序继续执行的函数。对于C++开发人员最感兴趣的特性是,协程理想情况下不会占用堆栈空间... C#已经可以使用await和yield实现类似的功能,但C++可能需要重新构建才能实现。
并发(concurrency)主要关注程序应该完成的任务,其中一个任务被称为一个关注点。这种关注点的分离可以通过多种方式来实现...通常是通过委托来实现。并发的思想是让多个进程独立运行(关注点的分离),并且“监听器”将由这些分离的关注点产生的任何内容定向到其应该去的地方。这在很大程度上依赖于某种异步管理。并发有许多方法,包括面向方面编程等。C#具有“委托”运算符,可以很好地工作。
并行(parallelism)听起来像并发,并且可能涉及,但实际上它是一个物理结构,涉及许多处理器以更或多或少并行的方式排列,配合软件将代码的部分指向不同的处理器,其中将被运行并接收结果。