是否可以在不完全下载ZIP文件的情况下读取其内容?
我正在构建一个爬虫,我不想为了索引它们的内容而下载每个zip文件。
谢谢;
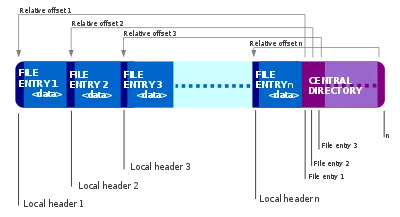
该格式表明文件中包含的信息关键部分位于其末尾。然后,条目被指定为相对于该特定条目的偏移量,因此您需要访问整个文件。
GZip格式可以作为流读取。
.tar.gz:.tar 组合文件并将它们压缩成 .gz 的原因。 - Samuel Neff这是可能的。您需要的只是允许按范围读取字节、获取结束记录(以了解 CD 的大小)、获取中央目录(以了解文件的起始位置和结束位置),然后获取适当的字节并处理它们的服务器。
以下是 Python 实现:onlinezip
[完全披露:我是该库的作者]
在ArchView中实现了一种解决方案:“ArchView可以在线打开存档文件,而无需下载整个存档。” https://addons.mozilla.org/en-US/firefox/addon/5028/
在archview-0.7.1.xpi文件中的“archview.js”文件中,您可以查看他们的JavaScript方法。
我不知道这是否有帮助,因为我不是程序员。但在Outlook中,您可以预览zip文件并查看实际内容,而不仅仅是文件目录(如果它们是可预览的文档,如pdf)。