我正在寻找一种高效的数据结构来表示优先级列表。具体而言,我需要为一组项目分配优先级,并仅返回得分最高的项目。我已经研究了基于堆的优先队列,但它们似乎并不真正适合我的需求。它们将在我从队列中轮询顶部评分项目时重新组织堆结构。
当然,最简单的解决方案是使用链表,但在最坏情况下插入操作可能需要很长时间。
有没有更好的解决方案?
当然,最简单的解决方案是使用链表,但在最坏情况下插入操作可能需要很长时间。
有没有更好的解决方案?
JDK内置了一个pqueue类(java.util.PriorityQueue),它基于堆算法。
抱歉,我刚才才看到堆不符合您的需求的部分。您能解释一下原因吗?您可以编写自定义比较器(或使您的项目可比较),PriorityQueue将适当地对您的项目进行排序。
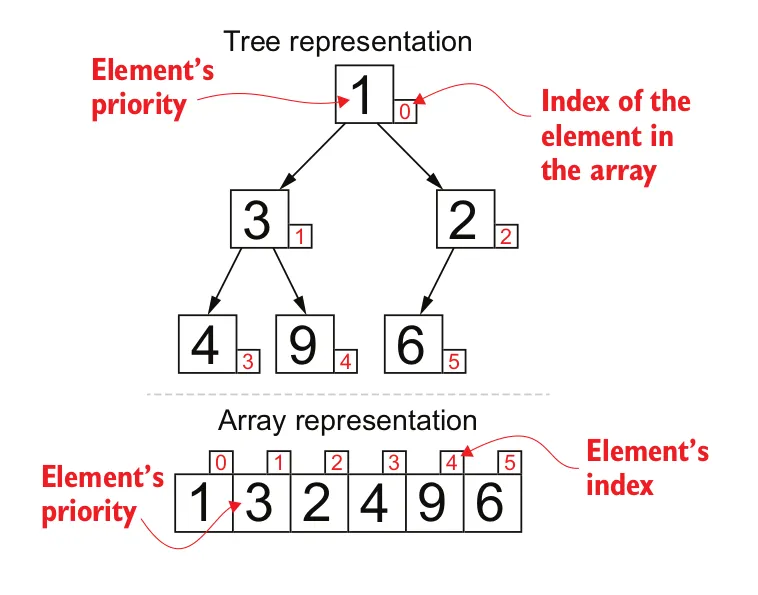
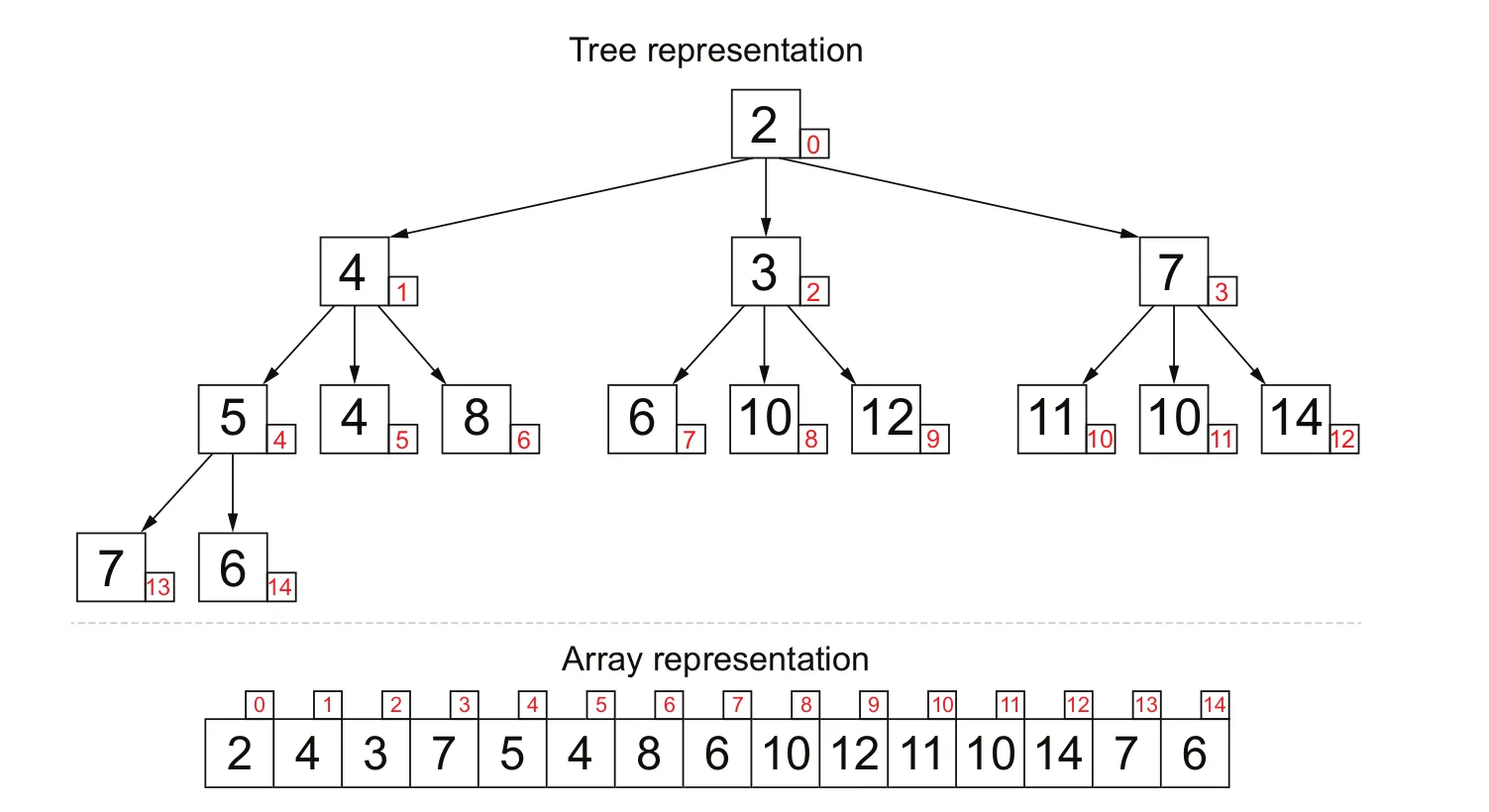
每个节点最多有两个子节点。
堆树是完全且左调整的。完全意味着如果堆的高度为H,则每个叶节点位于级别H或H-1。所有级别都是左调整的,这意味着没有右子树的高度大于其左兄弟。因此,如果一个叶子与内部节点处于相同的高度,则该叶子不能在该节点的左侧。
每个节点保存其子树中具有最高优先级的值。