我正在尝试读取一个二进制序列化对象,但我没有这个对象的定义/源代码。我瞥了一眼文件,看到了属性名称,因此我手动重新创建了该对象(我们称之为
最终得到的是:
现在我可以像这样反序列化它:
首先可疑的事情是,在反序列化的data对象中,只有2个字符串(
第二个可疑的事情是,如果我重新序列化此对象,最终得到的文件大小会不同。原始大小为695字节,而重新序列化后的对象大小为698字节,相差3字节。我应该得到与原始文件相同的文件大小。
查看原始文件和新的(重新序列化的)文件:
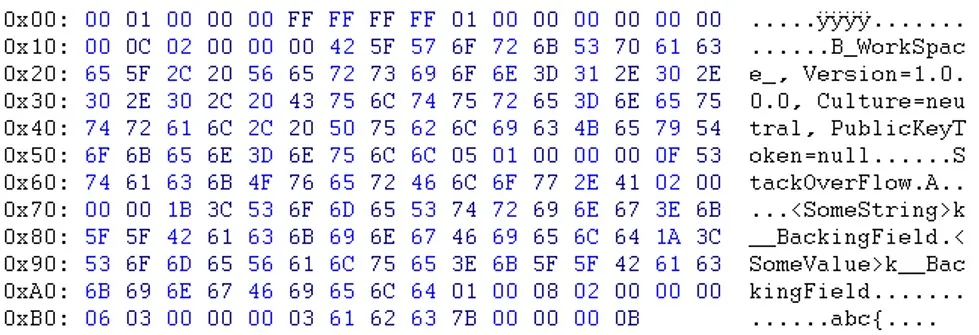
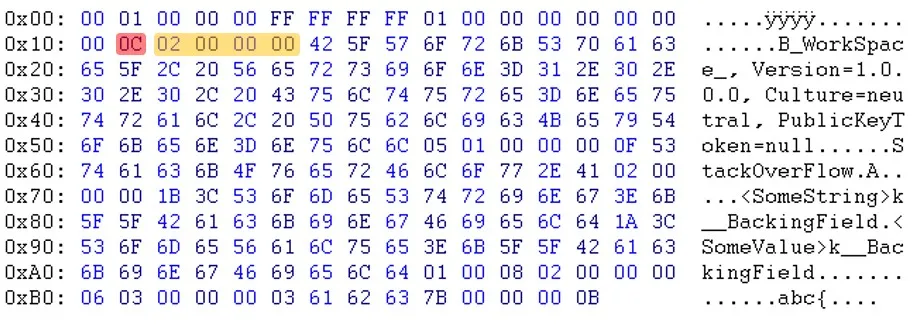
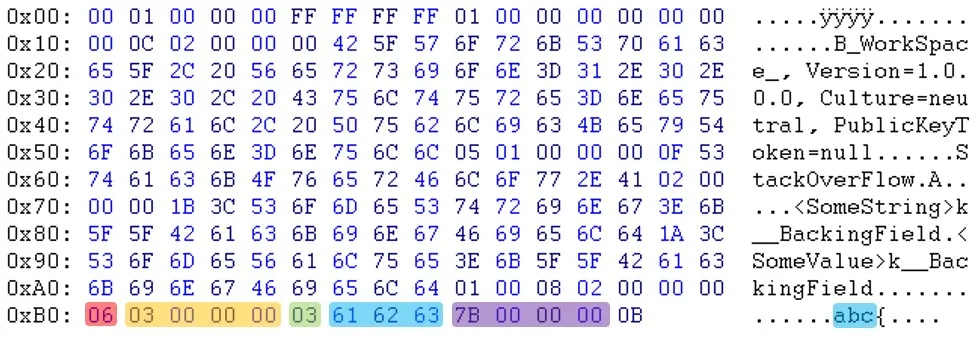
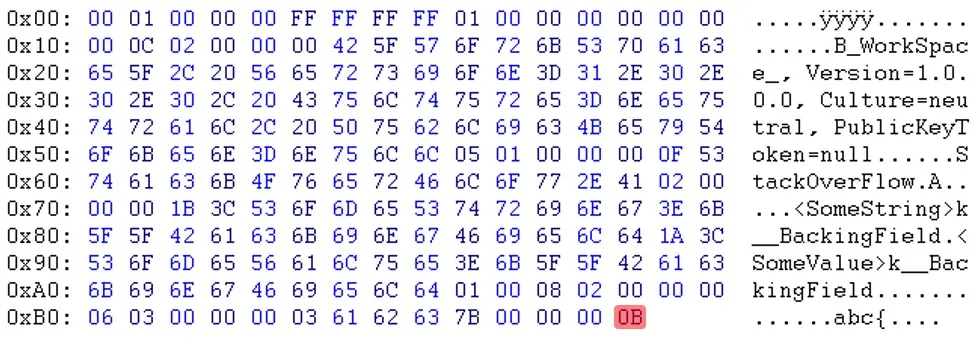
原始序列化文件:(zoom) 重新序列化文件:(zoom)
重新序列化文件:(zoom)
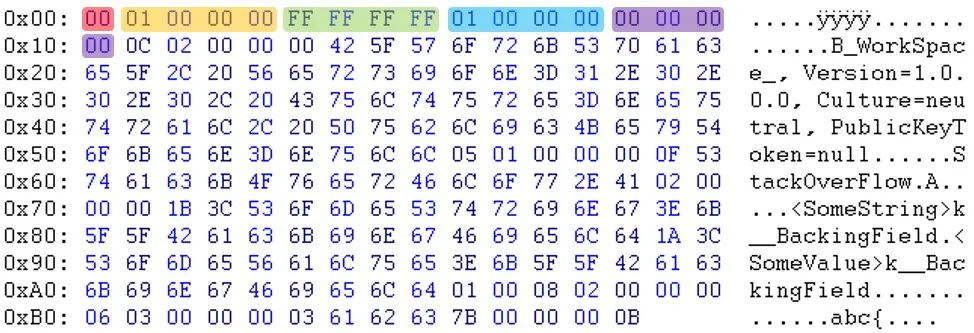
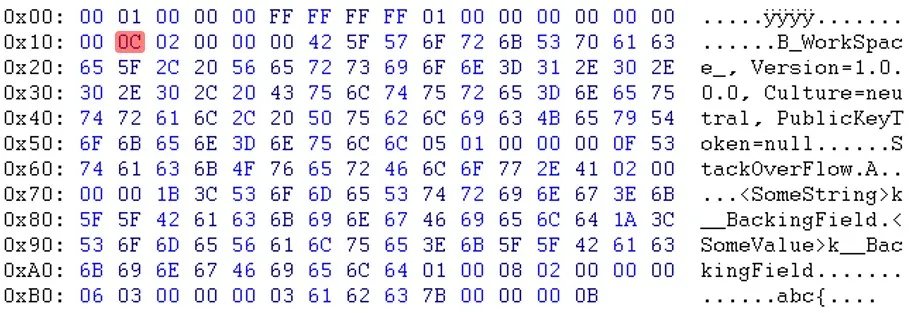
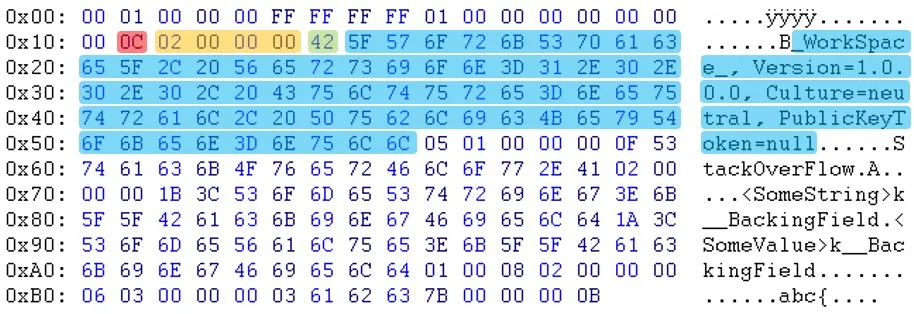
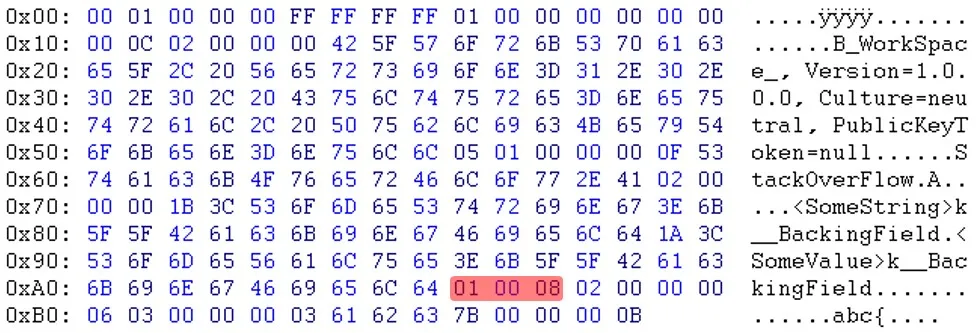
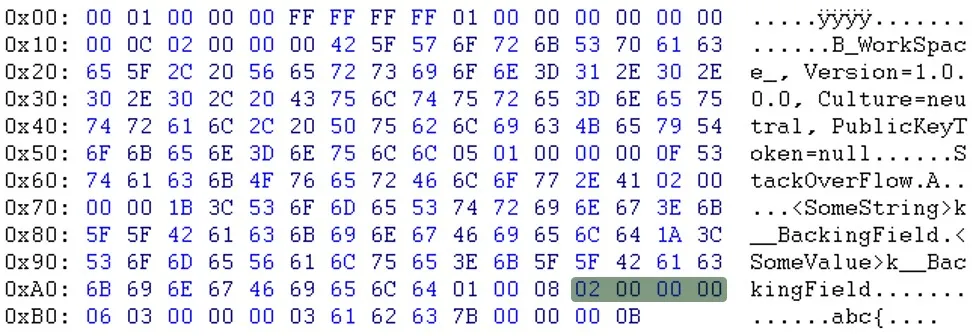
 如您所见,在标题部分之后,数据似乎是以不同的顺序出现的。例如,您可以看到电子邮件和sessionID不在同一位置。
如您所见,在标题部分之后,数据似乎是以不同的顺序出现的。例如,您可以看到电子邮件和sessionID不在同一位置。
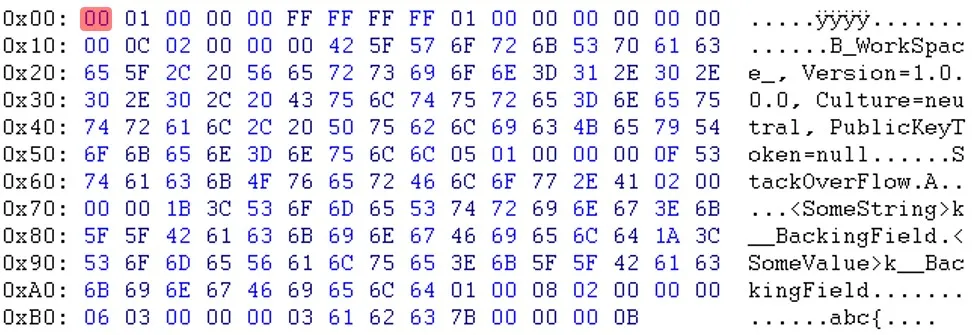
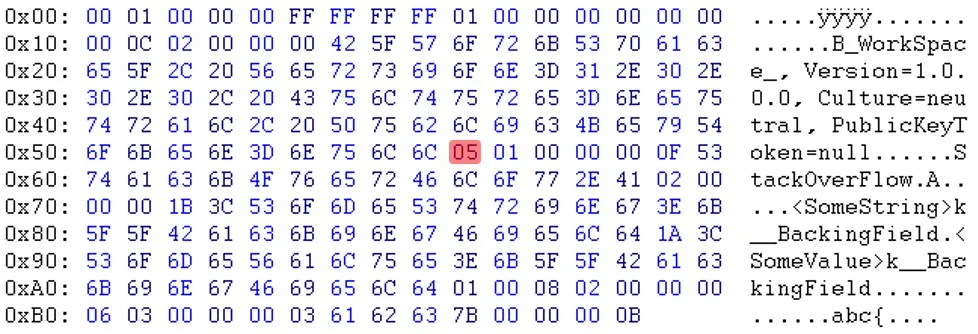
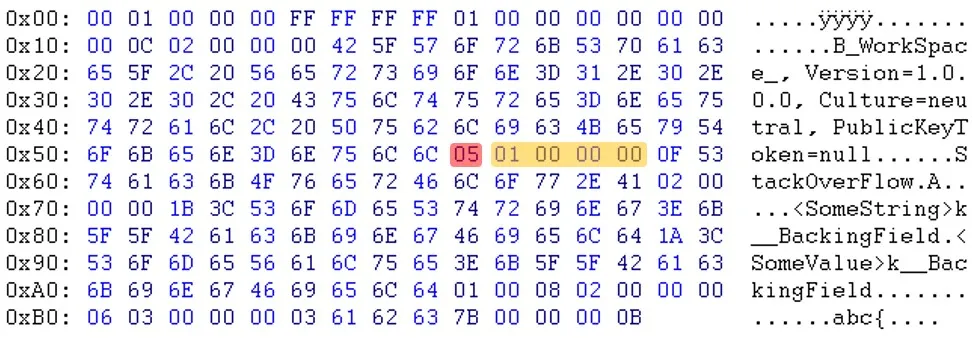
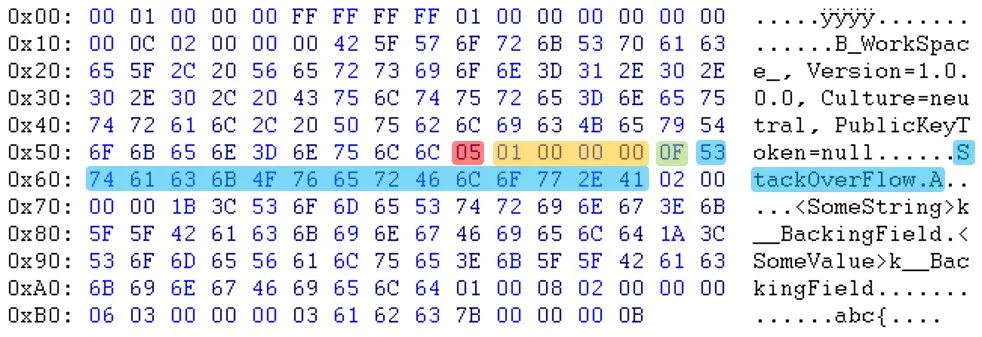
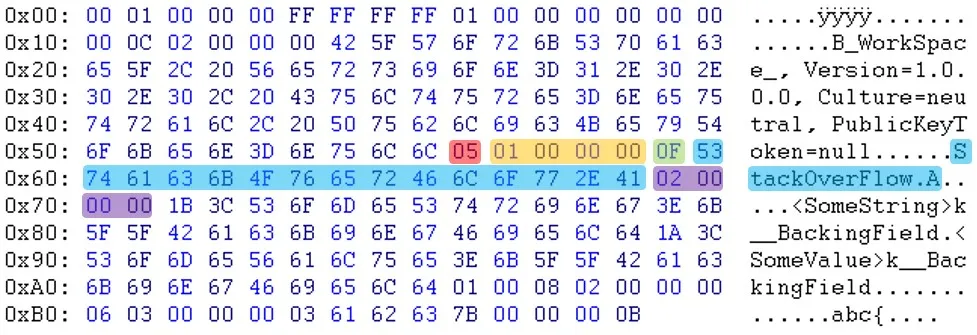
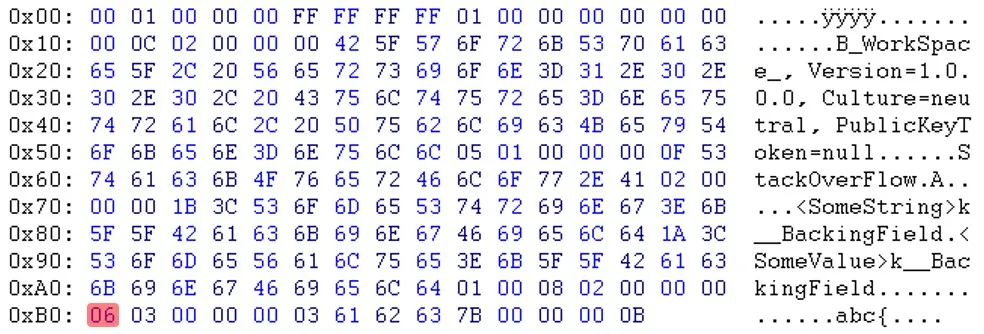
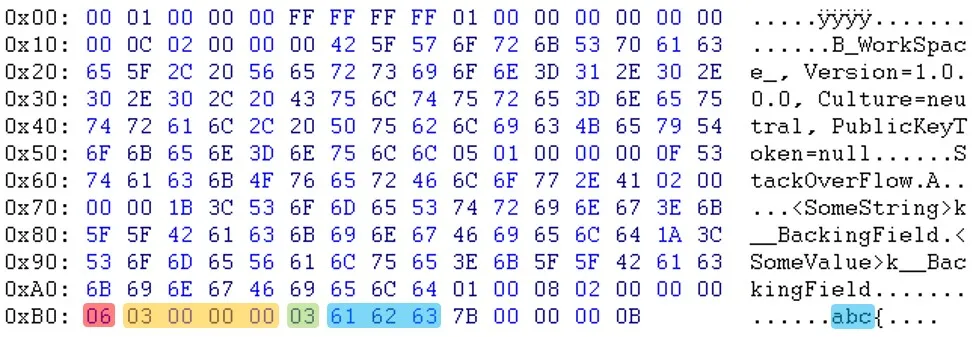
更新:Will提醒我,“PublicKeyToken=null”之后的字节也不同。(03 <-> 05)
Q1:为什么两个文件中的值顺序不同?
Q2:相比2个序列化对象,为什么会有额外的3个字节?
Q3:我错过了什么?我该如何处理?
感谢您的任何帮助。
SomeDataFormat)。最终得到的是:
public class SomeDataFormat // 16 field
{
public string Name{ get; set; }
public int Country{ get; set; }
public string UserEmail{ get; set; }
public bool IsCaptchaDisplayed{ get; set; }
public bool IsForgotPasswordCaptchaDisplayed{ get; set; }
public bool IsSaveChecked{ get; set; }
public string SessionId{ get; set; }
public int SelectedLanguage{ get; set; }
public int SelectedUiCulture{ get; set; }
public int SecurityImageRefId{ get; set; }
public int LogOnId{ get; set; }
public bool BetaLogOn{ get; set; }
public int Amount{ get; set; }
public int CurrencyTo{ get; set; }
public int Delivery{ get; set; }
public bool displaySSN{ get; set; }
}
现在我可以像这样反序列化它:
BinaryFormatter formatter = new BinaryFormatter();
formatter.AssemblyFormat = FormatterAssemblyStyle.Full; // original uses this
formatter.TypeFormat = FormatterTypeStyle.TypesWhenNeeded; // this reduces size
FileStream readStream = new FileStream("data.dat", FileMode.Open);
SomeDataFormat data = (SomeDataFormat) formatter.Deserialize(readStream);
首先可疑的事情是,在反序列化的data对象中,只有2个字符串(
SessionId和UserEmail)具有值。其他属性为null或仅为0。这可能是有意的,但我仍然怀疑在反序列化过程中出现了问题。第二个可疑的事情是,如果我重新序列化此对象,最终得到的文件大小会不同。原始大小为695字节,而重新序列化后的对象大小为698字节,相差3字节。我应该得到与原始文件相同的文件大小。
查看原始文件和新的(重新序列化的)文件:
原始序列化文件:(zoom)
重新序列化文件:(zoom)
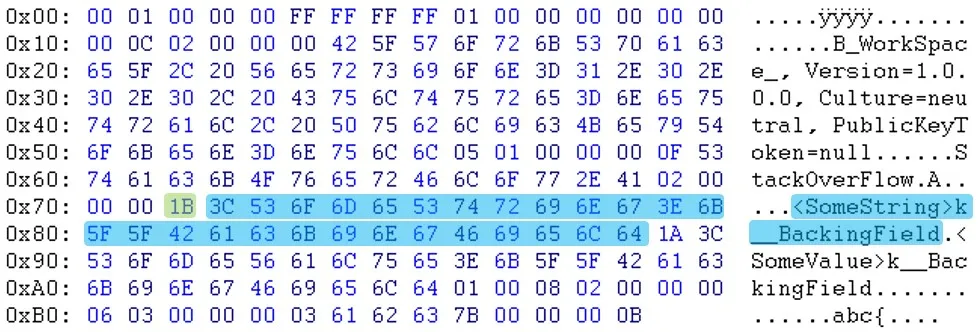
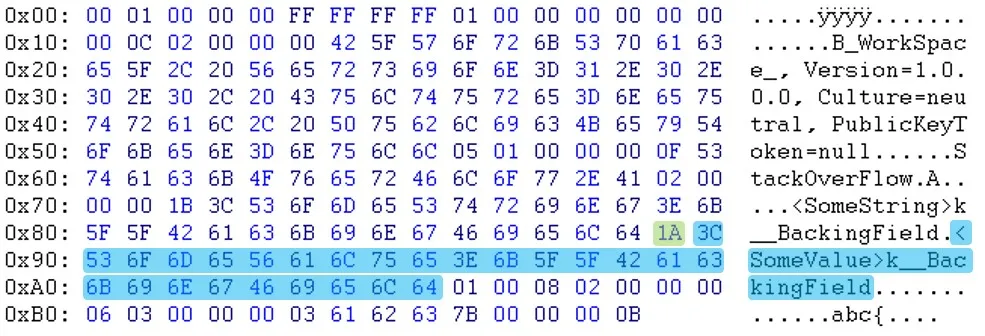
如您所见,在标题部分之后,数据似乎是以不同的顺序出现的。例如,您可以看到电子邮件和sessionID不在同一位置。更新:Will提醒我,“PublicKeyToken=null”之后的字节也不同。(03 <-> 05)
Q1:为什么两个文件中的值顺序不同?
Q2:相比2个序列化对象,为什么会有额外的3个字节?
Q3:我错过了什么?我该如何处理?
感谢您的任何帮助。
 "
" "
"

Data_reSerialized.dat是否能够进行反序列化,并报告它所产生的序列化大小;即Data_reReSerialized.dat的大小是多少? - Mark Hurd