在什么情况下使用JPA的@JoinTable注解?
何时使用JPA的@JoinTable注释?
192
- kostas trichas
5个回答
441
编辑 2017-04-29: 正如一些评论者所指出的那样,JoinTable 示例不需要使用 mappedBy 注释属性。事实上,最近版本的 Hibernate 会拒绝启动并打印以下错误:
org.hibernate.AnnotationException:
Associations marked as mappedBy must not define database mappings
like @JoinTable or @JoinColumn
假设你有一个名为Project的实体和另一个名为Task的实体,每个项目可以有很多任务。
你可以用两种方法设计这种情形的数据库模式。
第一种解决方案是创建一个名为Project的表和另一个名为Task的表,并在任务表中添加一个名为project_id的外键列:
Project Task
------- ----
id id
name name
project_id
这样,就可以确定任务表中每一行所属的项目。如果采用这种方法,在实体类中将不需要使用联接表:
@Entity
public class Project {
@OneToMany(mappedBy = "project")
private Collection<Task> tasks;
}
@Entity
public class Task {
@ManyToOne
private Project project;
}
Project_Tasks,并在该表中存储项目和任务之间的关系:Project Task Project_Tasks
------- ---- -------------
id id project_id
name name task_id
Project_Tasks表被称为“关联表”。要在JPA中实现第二种解决方案,您需要使用@JoinTable注释。例如,为了实现单向一对多的关联,我们可以定义如下的实体:
Project实体:
@Entity
public class Project {
@Id
@GeneratedValue
private Long pid;
private String name;
@JoinTable
@OneToMany
private List<Task> tasks;
public Long getPid() {
return pid;
}
public void setPid(Long pid) {
this.pid = pid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Task> getTasks() {
return tasks;
}
public void setTasks(List<Task> tasks) {
this.tasks = tasks;
}
}
Task 实体:
@Entity
public class Task {
@Id
@GeneratedValue
private Long tid;
private String name;
public Long getTid() {
return tid;
}
public void setTid(Long tid) {
this.tid = tid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
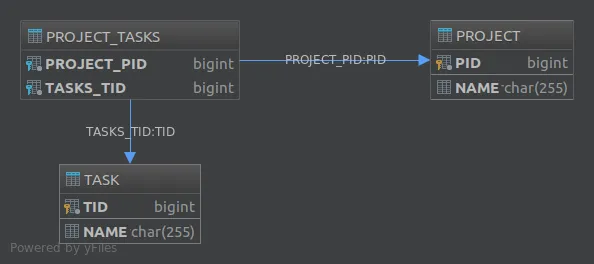 @JoinTable注解还允许您自定义连接表的各个方面。例如,如果我们像这样注释了tasks属性:
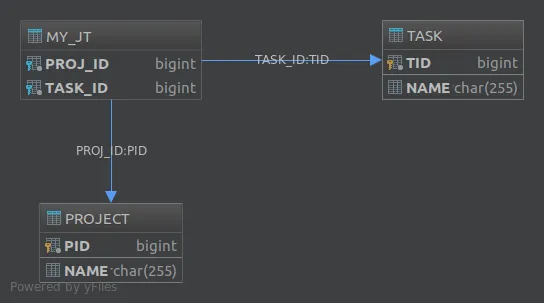
@JoinTable注解还允许您自定义连接表的各个方面。例如,如果我们像这样注释了tasks属性:@JoinTable(
name = "MY_JT",
joinColumns = @JoinColumn(
name = "PROJ_ID",
referencedColumnName = "PID"
),
inverseJoinColumns = @JoinColumn(
name = "TASK_ID",
referencedColumnName = "TID"
)
)
@OneToMany
private List<Task> tasks;
得到的数据库将如下所示:
最后,如果你想为多对多关联创建模式,则使用连接表是唯一可用的解决方案。
- Behrang
18
29
@ManyToMany关联
通常情况下,您需要使用@JoinTable注释来指定多对多表关系的映射:
- 链接表的名称
- 两个外键列
因此,假设您有以下数据库表:

在Post实体中,您可以像这样映射此关系:
@ManyToMany(cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
})
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private List<Tag> tags = new ArrayList<>();
@JoinTable注释用于通过name属性指定表名,以及参考post表的外键列(例如,joinColumns)和参考Tag实体的inverseJoinColumns属性的post_tag链接表中的外键列。请注意,
@ManyToMany注释的级联属性仅设置为PERSIST和MERGE,因为级联REMOVE是一个坏主意,因为在我们的情况下将发出tag的DELETE语句到post_tag记录而不是另一个父记录。
单向@OneToMany关联
缺乏@JoinColumn映射的单向@OneToMany关联表现得像多对多表关系,而不是一对多关系。
因此,假设您具有以下实体映射:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
@Id
@GeneratedValue
private Long id;
private String title;
@OneToMany(
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
//Constructors, getters and setters removed for brevity
}
@Entity(name = "PostComment")
@Table(name = "post_comment")
public class PostComment {
@Id
@GeneratedValue
private Long id;
private String review;
//Constructors, getters and setters removed for brevity
}
对于上述实体映射,Hibernate将假定以下数据库模式:

如前所述,单向@OneToMany JPA映射的行为类似于多对多关联。
要自定义链接表,您还可以使用@JoinTable注释:
@OneToMany(
cascade = CascadeType.ALL,
orphanRemoval = true
)
@JoinTable(
name = "post_comment_ref",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "post_comment_id")
)
private List<PostComment> comments = new ArrayList<>();
现在,链接表将被称为post_comment_ref,外键列将是post_id,用于关联post表,以及post_comment_id,用于关联post_comment表。
单向的
@OneToMany关联不够高效,最好使用双向的@OneToMany关联或只使用@ManyToOne面。
- Vlad Mihalcea
4
17
在映射ManyToMany关系时,必须使用join table(连接表)来实现:需要在两个实体表之间创建一个join table来映射关联关系。
同时,在OneToMany(通常是单向的)关联中,如果您不想在many side的表中添加外键,以便保持其独立性,则也会使用join table。
要查找@JoinTable在Hibernate文档中的解释和示例。
- JB Nizet
1
嗨,对于多对多关联,这不是唯一的解决方案。您可以创建一个带有两个双向
@OneToMany 关联的连接实体。 - Arash15
如果一个实体可以是多个父/子关系中的子项,且这些父类类型不同,则使用@JoinTable更加清晰。举个例子,如果一个任务可以是项目、人员、部门、研究和流程的子项。
那么task表是否需要5个nullable外键字段呢?我认为不需要...
- Dave
7
它可以帮助你处理多对多关系。例如:
Table 1: post
post has following columns
____________________
| ID | DATE |
|_________|_________|
| | |
|_________|_________|
Table 2: user
user has the following columns:
____________________
| ID |NAME |
|_________|_________|
| | |
|_________|_________|
“Join Table”允许您使用以下内容创建映射:
@JoinTable(
name="USER_POST",
joinColumns=@JoinColumn(name="USER_ID", referencedColumnName="ID"),
inverseJoinColumns=@JoinColumn(name="POST_ID", referencedColumnName="ID"))
将创建一个表:
____________________
| USER_ID| POST_ID |
|_________|_________|
| | |
|_________|_________|
- slal
3
2问题:如果我已经有了这个额外的表,JoinTable不会覆盖现有的表,对吗? - TheWandererr
@TheWandererr,你找到问题的答案了吗?我已经有一个连接表了。 - asgs
在我的情况下,它会在拥有方表中创建一个冗余列。例如,在POST中的POST_ID。你能建议这是为什么吗? - SPS
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 8 JPA: @ManyToMany @JoinTable映射关系的隐式级联作用是什么?
- 4 使用Spring 3+Hibernate JPA时发现JPA注释的类
- 50 JPA何时设置@GeneratedValue@Id?
- 7 何时使用Hibernate/JPA/Toplink?
- 36 何时应该在JPA中使用@JoinColumn或@JoinTable?
- 7 使用@JoinTable时保持JPA ManyToMany列表顺序
- 7 Hibernate:何时使用@Index注释
- 10 JPA ManyToMany,JoinTable如何拥有属性?
- 27 何时使用Jersey的@Singleton注释?
- 5 何时应使用安全注释“denyAll”?
@JoinTable/@JoinColumn可以与mappedBy一起注释在同一个字段上。因此,正确的示例应该保留Project中的mappedBy,并将@JoinColumn移动到Task.project(或反之亦然)。 - Adrian ShumProject_Tasks还需要Task的name,这将变成三列:project_id,task_id,task_name,如何实现? - macemersCaused by: org.hibernate.AnnotationException: Associations marked as mappedBy must not define database mappings like @JoinTable or @JoinColumn:。 - karthik m