数据仓库中有40张表。每天在每日数据加载后,我都会检查这些表是否存在任何数据问题。为了找到重复数据,我使用select查询来实现。
SELECT COALESCE (SUM(DUPS),0) AS DUPS_COUNT, 'PLAYER' AS TABLENAME FROM (Select Count(1) AS DUPS from DW.PLAYER group by PLAYERID having count(1) > 1) A
UNION
SELECT COALESCE (SUM(DUPS),0) AS DUPS_COUNT, 'PlayerBalance' AS TABLENAME FROM (Select Count(1) AS DUPS from DW.PlayerBalance group by PlayerID,SiteID having count(1) > 1) B
UNION
.
.
.
.
.
UNION
SELECT COALESCE (SUM(DUPS),0) AS DUPS_COUNT, 'TABLE40' AS TABLENAME FROM (Select Count(1) AS DUPS from DW.TABLE40 group by PLAYERID having count(1) > 1) AK
一个表的示例输出:
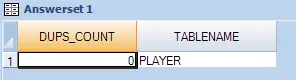
我有用于查找40个表中重复数据的选择查询。所有40个单独的选择语句在逻辑上和语法上都是正确的。但是,我没有逐个运行SQL选择,而是为每个表创建了一个公共格式,并对所有40个选择查询进行了UNION操作。
当运行包含这40个选择查询结合的UNION的查询时,只会显示16张表的输出,而不是40张表。
如何修复才能一次性搜索所有40张表中的重复数据?
UNION ALL而不是UNION。对于您查询中的值,这不会有问题。但是在实际查询中,您可能会有重复的表名。 - Gordon Linoff