让我们使用 timeit 进行适当的基准测试,并且为了轻松比较不同的 Python 版本,让我们在 Docker 容器中运行:
so62514160.py
N = 1000000
def m1():
s = 0
for i in range(N):
s += i
def m2():
s = sum(i for i in range(N))
def m3():
s = sum(range(N))
so62514160bench.sh
for image in python:2.7 python:3.6 python:3.7 python:3.8; do
for fun in m1 m2 m3; do
echo -n "$image" "$fun "
docker run --rm -it -v $(pwd):/app -w /app -e PYTHONDONTWRITEBYTECODE=1 "$image" python -m timeit -s 'import so62514160 as s' "s.$fun()"
done
done
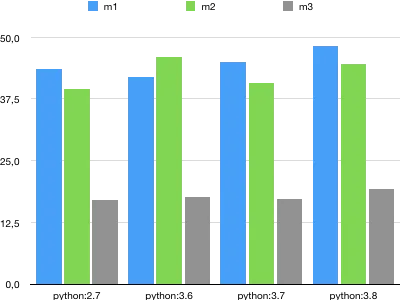
我的机器上的结果:
python:2.7 m1 10 loops, best of 3: 43.5 msec per loop
python:2.7 m2 10 loops, best of 3: 39.6 msec per loop
python:2.7 m3 100 loops, best of 3: 17.1 msec per loop
python:3.6 m1 10 loops, best of 3: 41.9 msec per loop
python:3.6 m2 10 loops, best of 3: 46 msec per loop
python:3.6 m3 100 loops, best of 3: 17.7 msec per loop
python:3.7 m1 5 loops, best of 5: 45 msec per loop
python:3.7 m2 5 loops, best of 5: 40.7 msec per loop
python:3.7 m3 20 loops, best of 5: 17.3 msec per loop
python:3.8 m1 5 loops, best of 5: 48.2 msec per loop
python:3.8 m2 5 loops, best of 5: 44.6 msec per loop
python:3.8 m3 10 loops, best of 5: 19.2 msec per loop
绘图
sum的隐式循环和for的显式循环)。消除不必要的for循环可以将速度提高三倍:sum(range(1000000))。 - Tom Karzessum(range(1000000))更快:您不需要使用生成器表达式迭代range对象,以便sum具有可迭代对象。 - chepnersum(range(...))比生成器版本又快了两倍。 - chepner