我在这里修改我的答案,基于你最后发布的新信息。
from utils import *
import time
import numpy as np
from mxnet import nd, autograd, gluon
from mxnet.gluon import nn, rnn
import mxnet as mx
import datetime
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import math
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
context = mx.cpu(); model_ctx=mx.cpu()
mx.random.seed(1719)
def parser(x):
return datetime.datetime.strptime(x,'%Y-%m-%d')
import yfinance as yf
start = '2018-01-01'
end = '2020-04-22'
data = yf.download('GS', start, end)
data = data.reset_index()
data
data.dtypes
data = data.rename(columns={"Adj Close": "Adj_Close"})
data
num_training_days = int(data.shape[0]*.7)
print('Number of training days: {}. Number of test days: {}.'.format(num_training_days, data.shape[0]-num_training_days))
data['ma7'] = data['Adj_Close'].rolling(window=7).mean()
data['ma21'] = data['Adj_Close'].rolling(window=21).mean()
data['26ema'] = data['Adj_Close'].ewm(span=26).mean()
data['12ema'] = data['Adj_Close'].ewm(span=12).mean()
data['MACD'] = (data['12ema']-data['26ema'])
data['20sd'] = data['Adj_Close'].rolling(window=20).std()
data['upper_band'] = data['ma21'] + (data['20sd']*2)
data['lower_band'] = data['ma21'] - (data['20sd']*2)
data['ema'] = data['Adj_Close'].ewm(com=0.5).mean()
data['momentum'] = data['Adj_Close']-1
dataset_TI_df = data
dataset = data
def plot_technical_indicators(dataset, last_days):
plt.figure(figsize=(16, 10), dpi=100)
shape_0 = dataset.shape[0]
xmacd_ = shape_0-last_days
dataset = dataset.iloc[-last_days:, :]
x_ = range(3, dataset.shape[0])
x_ =list(dataset.index)
plt.subplot(2, 1, 1)
plt.plot(dataset['ma7'],label='MA 7', color='g',linestyle='--')
plt.plot(dataset['Adj_Close'],label='Closing Price', color='b')
plt.plot(dataset['ma21'],label='MA 21', color='r',linestyle='--')
plt.plot(dataset['upper_band'],label='Upper Band', color='c')
plt.plot(dataset['lower_band'],label='Lower Band', color='c')
plt.fill_between(x_, dataset['lower_band'], dataset['upper_band'], alpha=0.35)
plt.title('Technical indicators for Goldman Sachs - last {} days.'.format(last_days))
plt.ylabel('USD')
plt.legend()
plt.subplot(2, 1, 2)
plt.title('MACD')
plt.plot(dataset['MACD'],label='MACD', linestyle='-.')
plt.hlines(15, xmacd_, shape_0, colors='g', linestyles='--')
plt.hlines(-15, xmacd_, shape_0, colors='g', linestyles='--')
plt.legend()
plt.show()
plot_technical_indicators(dataset_TI_df, 400)
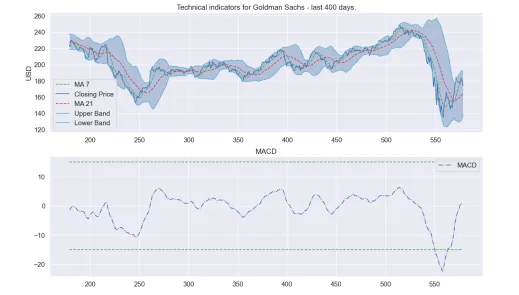
这将给你一些可以使用的信号。当然,这些特征可以是任何你想要的。我相信你知道这是技术分析,而不是基本面分析。现在,你可以进行聚类或其他你想做的事情了。
这里有一个好的聚类链接。
https://www.pythonforfinance.net/2018/02/08/stock-clusters-using-k-means-algorithm-in-python/