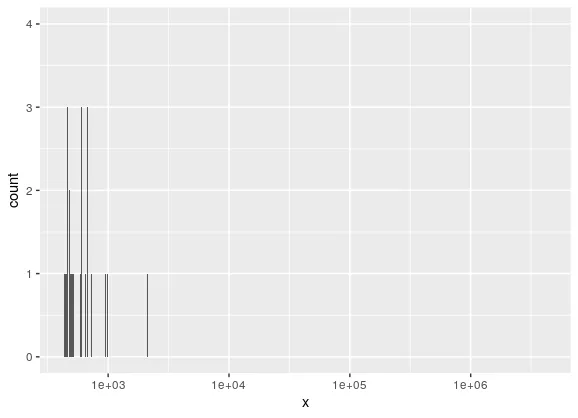
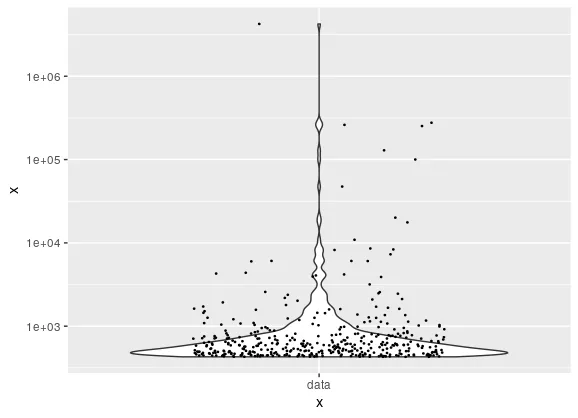
我很惊讶geom_histogram在我的机器上不能按预期工作。我有一个具有以下特点的数据集:
> dim(f)
[1] 102095 1
> max(f)
[1] 4239900
> min(f)
[1] -99.95
> mean(f$f)
[1] 74.21676
如您所见,下限被限制在 -100,而上限则几乎没有限制。 当我尝试以下代码:
hst = ggplot(f, aes(x = f)) + geom_histogram(binwidth = 50)
hst
我看到了这个输出:
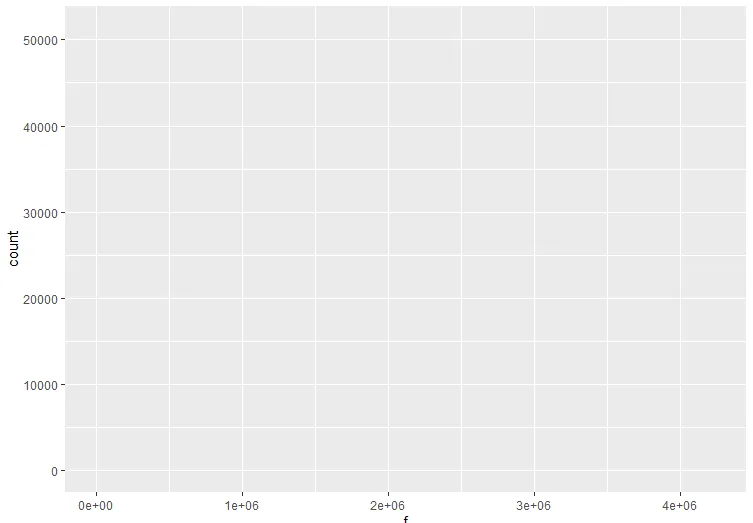
有人能告诉我发生了什么事情以及为什么geom_histogram失败了吗?
抱歉,陋陋的dput。
> dput(fff)
structure(list(NA. = c(4239899.5, 276432.13, 260769.56, 252399.97,
129099.98, 100070.3, 47400, 20083.34, 17600, 10900, 8566.67,
8343.33, 8220, 7285.72, 6076.47, 6066.25, 6053.85, 6000, 4380,
4281.82, 4181.88, 4066.67, 3950, 3900, 3175, 2578.28, 2565, 2480.65,
2454.26, 2381.48, 2185.71, 2116.84, 2091.84, 2021.82, 1929.63,
1795.68, 1721.57, 1713.19, 1664, 1625, 1616.36, 1605.56, 1589.6,
1573.73, 1513.79, 1448.6, 1448.57, 1433.33, 1380, 1359.8, 1358.33,
1275.31, 1263.64, 1262.07, 1258.73, 1237.5, 1211.76, 1186.36,
1168.35, 1143.75, 1133.32, 1130, 1116.67, 1094.44, 1089.93, 1076.92,
1076.54, 1064.02, 1045.1, 1037.97, 1032.91, 1026.7, 1020, 992.23,
987.87, 984.43, 975, 973.22, 971.07, 953.57, 951.72, 944, 919.44,
916.67, 914.84, 892.37, 886.67, 885.08, 866.22, 864.29, 847.76,
834.19, 827.37, 820, 815.57, 815, 812.9, 811.11, 809.09, 803.23,
802.02, 789.36, 788.89, 779.7, 779.55, 779.52, 779.01, 774.02,
768.29, 766.67, 765.6, 762.19, 760.93, 760.93, 759.57, 758.62,
757.58, 754.19, 751.82, 745.96, 739.27, 737.93, 730.47, 728.57,
727.07, 725.33, 724.78, 724.32, 723.79, 717.65, 713.19, 712.03,
711.46, 711.11, 710, 709.3, 708.82, 692.31, 692.04, 686.43, 681.82,
675.84, 675.13, 675.09, 675, 671.83, 666.67, 664.2, 661.9, 660.71,
660.62, 651.89, 651.87, 650.01, 649.75, 647.54, 646.31, 642.86,
640.47, 634.57, 632.67, 632.14, 630.07, 627.27, 627.27, 625.81,
625, 621.66, 621.13, 621.03, 617.91, 617.51, 616.46, 616.05,
614.54, 612.88, 611.11, 607.99, 607.75, 607.42, 606.63, 605.33,
604.89, 602.56, 602.55, 602.17, 601.87, 600.81, 598.75, 597.95,
597.44, 595.16, 594.45, 594.27, 592.19, 591.97, 591.6, 591.41,
590.78, 589.66, 589.04, 588.26, 586.74, 585.92, 584.85, 581.82,
581.75, 581.41, 580.46, 577.12, 576.54, 573.91, 572.53, 569.17,
568.54, 567.23, 567.22, 565.2, 565.06, 560.69, 560.68, 560.62,
558.91, 554.1, 553.85, 552.31, 551.04, 550, 545.65, 544.44, 544.39,
541.46, 541.3, 538.19, 538.19, 537.6, 537.22, 534.75, 534.41,
533.5, 531.6, 531.52, 531.25, 528.44, 524, 521.08, 518.14, 517.61,
517.46, 517.27, 516.67, 514.53, 513.71, 512.61, 511.11, 509.47,
508.86, 508.51, 507.82, 507.8, 507.79, 507.64, 506.94, 506.9,
506.32, 505.58, 505.06, 504.96, 503.37, 503.11, 502.36, 501.89,
501.09, 500.58, 499.18, 497.92, 497.02, 496.74, 496.24, 495.73,
495.08, 494.3, 491.67, 491.67, 490.65, 490.56, 489.96, 488.93,
488.18, 488.1, 487.72, 487.63, 486.33, 486.21, 485.45, 485.3,
482.53, 481.63, 481.4, 480.39, 479.06, 478.85, 477.55, 477.27,
476.94, 476.68, 476.46, 476.19, 473.47, 473.08, 472.99, 472.46,
471.43, 471.29, 471.11, 470.45, 467.35, 466.78, 466.44, 464.21,
464.08, 463.94, 463.54, 462.83, 462.32, 462.25, 461.37, 461.36,
461.32, 460.72, 460.48, 459.48, 459.37, 459.25, 458.82, 457.13,
456.4, 456.4, 455.7, 455.56, 455.48, 455.29, 455.25, 453.85,
452.36, 451.29, 450, 449.64, 449.22, 448.97, 448.39, 448.15,
447.96, 447.91, 447.66, 447.48, 447.41, 447.22, 447.16, 447.05,
447.01, 446.15, 445.74, 445.55, 445.54, 445.31, 445.18, 444.99,
444.74, 444.67, 444.22, 443.97, 443.41, 443.17, 441.59, 441.27,
441.08, 440.78, 439.53, 439.38, 439.25, 438.92, 438.6, 438.04,
437.89, 437.65, 437.5, 437.14, 436.97, 436.09, 436.03, 435.71,
435.17, 434.94, 434.82, 434.62, 434.45, 434.04, 433.46, 431.33,
431.11, 430.92, 430.6, 430.54, 429.54, 429.23, 429.1)), class = "data.frame", row.names = c(NA,
-407L))