从 Python 的运行效率角度来看,下面两个代码片段是否同样有效率?
x = foo()
x = bar(x)
VS
x = bar(foo())
我有一个更加复杂的问题,可以概括为这个问题:显然,从代码长度的角度来看,第二个选项更高效,但是运行时间是否更优秀呢?如果它们不是,为什么呢?
从 Python 的运行效率角度来看,下面两个代码片段是否同样有效率?
x = foo()
x = bar(x)
VS
x = bar(foo())
我有一个更加复杂的问题,可以概括为这个问题:显然,从代码长度的角度来看,第二个选项更高效,但是运行时间是否更优秀呢?如果它们不是,为什么呢?
以下是比较:
第一个案例:
%%timeit
def foo():
return "foo"
def bar(text):
return text + "bar"
def test():
x = foo()
y = bar(x)
return y
test()
#Output:
'foobar'
529 ns ± 114 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
第二种情况:
%%timeit
def foo():
return "foo"
def bar(text):
return text + "bar"
def test():
x = bar(foo())
return x
test()
#Output:
'foobar'
447 ns ± 34.6 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
但这只是对每种情况运行%%timeit一次的比较。以下是每种情况20次迭代的时间(以纳秒为单位):
df = pd.DataFrame({'First Case(time in ns)': [623,828,634,668,715,659,703,687,614,623,697,634,686,822,671,894,752,742,721,742],
'Second Case(time in ns)': [901,786,686,670,677,683,685,638,628,670,695,657,698,707,726,796,868,703,609,852]})
df.plot(kind='density', figsize=(8,8))
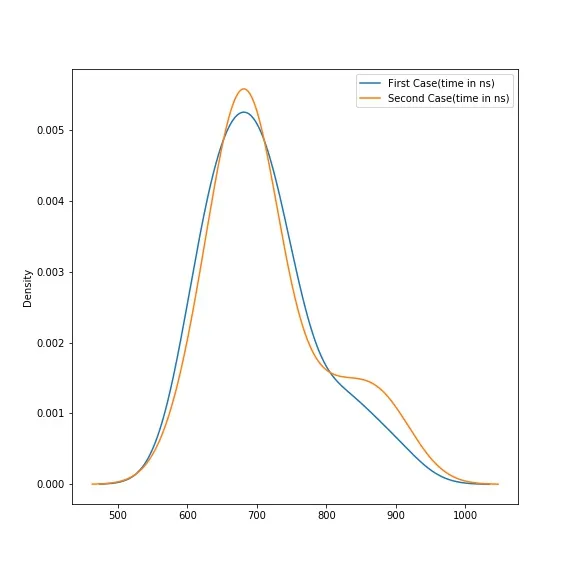
观察发现,随着每次迭代,差异逐渐减小。这张图表明性能差异不显著。从可读性的角度来看,第二种情况更加清晰。
在第一种情况中,两个表达式都被计算: 第一个表达式将foo()的返回值分配给x,然后第二个表达式调用该值上的bar()。这增加了一些开销。而在第二种情况下,只计算了一个表达式,同时调用了两个函数并返回值。
return bar(foo())的函数是否可能? - s_baldurfoo、bar和test,然后在每个循环中调用test一次,而在第二个案例中只定义了test并调用了一次。定义每个函数都会带来开销,但在实际应用中,除了main之外,通常不会计划调用任何函数恰好一次。你想计算的是调用成本,而不是定义函数的成本。如果你这样做,你会发现差异非常微不足道。 - ShadowRangermain,因此比较应该是针对函数调用而不是定义。我观察到,在每个测试中,图形都越来越接近,性能差异逐渐减小。 - amanbipython%%timeit魔术命令(IPython版本7.3.0,CPython版本3.7.2,适用于Linux x86-64),但从每个循环测试中删除函数的定义:>>> def foo():
... return "foo"
... def bar(text):
... return text + "bar"
... def inline():
... x = bar(foo())
... return x
... def outofline():
... x = foo()
... x = bar(x)
... return x
...
>>> %%timeit -r5 test = inline
... test()
...
...
332 ns ± 1.01 ns per loop (mean ± std. dev. of 5 runs, 1000000 loops each)
>>> %%timeit -r5 test = outofline
... test()
...
...
341 ns ± 5.62 ns per loop (mean ± std. dev. of 5 runs, 1000000 loops each)
inline"代码更快,但差异在10ns/3%以下。进一步内联(使主体仅为return bar(foo()))可以再节省一点点时间,但这仍然毫无意义。"outofline需要额外的STORE_FAST和LOAD_FAST(一个跟随另一个),而这些指令在内部实现时只是对C数组中编译时确定的插槽进行赋值和读取,再加上单个整数增量以调整引用计数。您需要为每个字节码所需的CPython解释器开销付费,但实际工作的成本微不足道。foo的输出命名一个有用的名称,然后将其传递给bar,其输出被赋予另一个有用的名称,并且没有这些名称,foo和bar之间的关系不明显,则不要内联。 如果关系是明显的,并且foo的输出不受命名的影响,请内联它。 避免从本地变量中存储和加载是最微小的微优化; 在几乎任何情况下,它都不会导致有意义的性能损失,因此不要基于此来进行代码设计决策。%%timeit的第一行来将每个测试函数别名为一个一致的本地名称,而不仅仅是测试%timeit -r5 inline()和%timeit -r5 outofline(),因为%%timeit的第一行定义了(没有计时)测试的本地变量,然后在该上下文中运行后续块。如果您使用原始名称,则最终会计算在全局命名空间中查找inline和outofline的成本,这并不是您关心的内容,并且由于哈希冲突,可能会无法预测地减慢某个选项的速度,而这并非其本身的问题。 - ShadowRanger