请看下面GPU独显代码示例:
#include <iostream>
#ifdef __APPLE__
#include <OpenCL/cl.h>
#else
#include <CL/cl.h>
#pragma comment (lib, "x86_64/opencl.lib")
#endif
const char* saxpy_kernel =
"__kernel \n"
"void saxpy_kernel(float alpha, \n"
" __global float *A, \n"
" __global float *B, \n"
" __global float *C) \n"
"{ \n"
" int idx = get_global_id(0); \n"
" C[idx] = alpha * A[idx] + B[idx]; \n"
"} ";
const char* clErrName[] = {
"CL_SUCCESS",
"CL_DEVICE_NOT_FOUND",
"CL_DEVICE_NOT_AVAILABLE",
"CL_COMPILER_NOT_AVAILABLE",
"CL_MEM_OBJECT_ALLOCATION_FAILURE",
"CL_OUT_OF_RESOURCES",
"CL_OUT_OF_HOST_MEMORY",
"CL_PROFILING_INFO_NOT_AVAILABLE",
"CL_MEM_COPY_OVERLAP",
"CL_IMAGE_FORMAT_MISMATCH",
"CL_IMAGE_FORMAT_NOT_SUPPORTED",
"CL_BUILD_PROGRAM_FAILURE",
"CL_MAP_FAILURE",
"CL_MISALIGNED_SUB_BUFFER_OFFSET",
"CL_EXEC_STATUS_ERROR_FOR_EVENTS_IN_WAIT_LIST",
"CL_COMPILE_PROGRAM_FAILURE",
"CL_LINKER_NOT_AVAILABLE",
"CL_LINK_PROGRAM_FAILURE",
"CL_DEVICE_PARTITION_FAILED",
"CL_KERNEL_ARG_INFO_NOT_AVAILABLE",
"CL_UNDEFINED_ERROR_20",
"CL_UNDEFINED_ERROR_21",
"CL_UNDEFINED_ERROR_22",
"CL_UNDEFINED_ERROR_23",
"CL_UNDEFINED_ERROR_24",
"CL_UNDEFINED_ERROR_25",
"CL_UNDEFINED_ERROR_26",
"CL_UNDEFINED_ERROR_27",
"CL_UNDEFINED_ERROR_28",
"CL_UNDEFINED_ERROR_29",
"CL_INVALID_VALUE",
"CL_INVALID_DEVICE_TYPE",
"CL_INVALID_PLATFORM",
"CL_INVALID_DEVICE",
"CL_INVALID_CONTEXT",
"CL_INVALID_QUEUE_PROPERTIES",
"CL_INVALID_COMMAND_QUEUE",
"CL_INVALID_HOST_PTR",
"CL_INVALID_MEM_OBJECT",
"CL_INVALID_IMAGE_FORMAT_DESCRIPTOR",
"CL_INVALID_IMAGE_SIZE",
"CL_INVALID_SAMPLER",
"CL_INVALID_BINARY",
"CL_INVALID_BUILD_OPTIONS",
"CL_INVALID_PROGRAM",
"CL_INVALID_PROGRAM_EXECUTABLE",
"CL_INVALID_KERNEL_NAME",
"CL_INVALID_KERNEL_DEFINITION",
"CL_INVALID_KERNEL",
"CL_INVALID_ARG_INDEX",
"CL_INVALID_ARG_VALUE",
"CL_INVALID_ARG_SIZE",
"CL_INVALID_KERNEL_ARGS",
"CL_INVALID_WORK_DIMENSION",
"CL_INVALID_WORK_GROUP_SIZE",
"CL_INVALID_WORK_ITEM_SIZE",
"CL_INVALID_GLOBAL_OFFSET",
"CL_INVALID_EVENT_WAIT_LIST",
"CL_INVALID_EVENT",
"CL_INVALID_OPERATION",
"CL_INVALID_GL_OBJECT",
"CL_INVALID_BUFFER_SIZE",
"CL_INVALID_MIP_LEVEL",
"CL_INVALID_GLOBAL_WORK_SIZE",
"CL_INVALID_PROPERTY",
"CL_INVALID_IMAGE_DESCRIPTOR",
"CL_INVALID_COMPILER_OPTIONS",
"CL_INVALID_LINKER_OPTIONS",
"CL_INVALID_DEVICE_PARTITION_COUNT",
"CL_INVALID_PIPE_SIZE",
"CL_INVALID_DEVICE_QUEUE",
};
const int MAX_ERR_CODE = 70;
inline bool __clCallSuccess(cl_int err_code, const char* source_file, const int source_line)
{
if (err_code == CL_SUCCESS)
return true;
if ((err_code > 0) || (err_code < -MAX_ERR_CODE))
std::clog << "\t - unknown CL error: " << err_code;
else
std::clog << "\t - CL call error: " << clErrName[-err_code];
std::clog << " [" << source_file << " : " << source_line << "]" << std::endl;
return false;
}
#define clCallSuccess(err_code) __clCallSuccess(err_code, __FILE__, __LINE__)
float cl_BenchmarkDevice(cl_context context, cl_command_queue command_queue, cl_device_id device_id)
{
float microSeconds = -1.;
int i;
cl_int clStatus;
const int VECTOR_SIZE = 512 * 1024;
float* A = (float*)malloc(sizeof(float) * VECTOR_SIZE); if(A) {
float* B = (float*)malloc(sizeof(float) * VECTOR_SIZE); if(B) {
float* C = (float*)malloc(sizeof(float) * VECTOR_SIZE); if(C) {
for (i = 0; i < VECTOR_SIZE; i++)
{
A[i] = (float)i;
B[i] = (float)(VECTOR_SIZE - i);
C[i] = 0;
}
cl_mem A_clmem = clCreateBuffer(context, CL_MEM_READ_ONLY, VECTOR_SIZE * sizeof(float), NULL, &clStatus); if (clCallSuccess(clStatus)) {
cl_mem B_clmem = clCreateBuffer(context, CL_MEM_READ_ONLY, VECTOR_SIZE * sizeof(float), NULL, &clStatus); if (clCallSuccess(clStatus)) {
cl_mem C_clmem = clCreateBuffer(context, CL_MEM_WRITE_ONLY, VECTOR_SIZE * sizeof(float), NULL, &clStatus); if (clCallSuccess(clStatus)) {
clStatus = clEnqueueWriteBuffer(command_queue, A_clmem, CL_TRUE, 0, VECTOR_SIZE * sizeof(float), A, 0, NULL, NULL); if (clCallSuccess(clStatus)) {
clStatus = clEnqueueWriteBuffer(command_queue, B_clmem, CL_TRUE, 0, VECTOR_SIZE * sizeof(float), B, 0, NULL, NULL); if (clCallSuccess(clStatus)) {
cl_program program = clCreateProgramWithSource(context, 1, (const char**)&saxpy_kernel, NULL, &clStatus); if (clCallSuccess(clStatus) && program) {
clStatus = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL); if (clCallSuccess(clStatus)) {
cl_kernel kernel = clCreateKernel(program, "saxpy_kernel", &clStatus); if (clCallSuccess(clStatus) && kernel) {
float alpha = 2.5;
clStatus = clSetKernelArg(kernel, 0, sizeof(float), (void*)&alpha); if (clCallSuccess(clStatus)) {
clStatus = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*)&A_clmem); if (clCallSuccess(clStatus)) {
clStatus = clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*)&B_clmem); if (clCallSuccess(clStatus)) {
clStatus = clSetKernelArg(kernel, 3, sizeof(cl_mem), (void*)&C_clmem); if (clCallSuccess(clStatus)) {
cl_event event;
size_t global_size = VECTOR_SIZE;
size_t local_size = 512;
clStatus = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, &global_size, NULL, 0, NULL, &event); if (clCallSuccess(clStatus)) {
clStatus = clWaitForEvents(1, &event); if (clCallSuccess(clStatus)) {
cl_ulong time_start;
cl_ulong time_end;
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_START, sizeof(time_start), &time_start, NULL);
clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_END, sizeof(time_end), &time_end, NULL);
microSeconds = (float)(time_end - time_start) / 1000.0f;
std::clog << "\nOpenCl benchmarking time: " << microSeconds << " microseconds \n";
std::clog << "\n\t*****************************\n\n";
}
clCallSuccess(clEnqueueReadBuffer(command_queue, C_clmem, CL_TRUE, 0, VECTOR_SIZE * sizeof(float), C, 0, NULL, NULL));
clCallSuccess(clFlush(command_queue));
clCallSuccess(clFinish(command_queue));
}
}}}}
clCallSuccess(clReleaseKernel(kernel)); }
}
clCallSuccess(clReleaseProgram(program)); }
} }
clCallSuccess(clReleaseMemObject(C_clmem)); }
clCallSuccess(clReleaseMemObject(B_clmem)); }
clCallSuccess(clReleaseMemObject(A_clmem)); }
free(C); }
free(B); }
free(A); }
return microSeconds;
}
cl_device_id cl_GetBestDevice(void)
{
cl_int err;
cl_uint numPlatforms, numDevices;
cl_platform_id platfIDs[10];
cl_device_id devIDsAll[10];
int countGPUs = 0;
cl_device_id best_device = NULL;
float best_perf = 100000000.;
if (clCallSuccess(clGetPlatformIDs(10, platfIDs, &numPlatforms)))
{
std::clog << "OpenCL platforms detected: " << numPlatforms << std::endl;
for (unsigned int i = 0; i < numPlatforms; i++)
{
std::clog << "PlatformInfo for platform no." << (i + 1) << std::endl;
const int SZ_INFO = 1024;
char info[SZ_INFO];
size_t sz;
if (clCallSuccess(clGetPlatformInfo(platfIDs[i], CL_PLATFORM_NAME, SZ_INFO, info, &sz)))
std::clog << " - - Name: " << info << std::endl;
if (clCallSuccess(clGetPlatformInfo(platfIDs[i], CL_PLATFORM_VENDOR, SZ_INFO, info, &sz)))
std::clog << " - - Vendor: " << info << std::endl;
if (clCallSuccess(clGetPlatformInfo(platfIDs[i], CL_PLATFORM_PROFILE, SZ_INFO, info, &sz)))
std::clog << " - - Profile: " << info << std::endl;
if (clCallSuccess(clGetPlatformInfo(platfIDs[i], CL_PLATFORM_VERSION, SZ_INFO, info, &sz)))
std::clog << " - - Version: " << info << std::endl;
if (clCallSuccess(clGetPlatformInfo(platfIDs[i], CL_PLATFORM_EXTENSIONS, SZ_INFO, info, &sz)))
std::clog << " - - Extensions: " << info << std::endl;
if (clCallSuccess(clGetDeviceIDs(platfIDs[i], CL_DEVICE_TYPE_ALL, 10, devIDsAll, &numDevices)))
{
cl_context_properties cProperties[] = { CL_CONTEXT_PLATFORM, (cl_context_properties)(platfIDs[i]), 0 };
cl_command_queue_properties qProperties[] = { CL_QUEUE_PROPERTIES, CL_QUEUE_PROFILING_ENABLE, 0 };
for (unsigned int ii = 0; ii < numDevices; ii++)
{
cl_uint val;
cl_ulong memsz;
cl_device_type dt;
size_t mws;
std::clog << " >> DeviceInfo for device no." << (ii + 1) << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_NAME, SZ_INFO, info, &sz)))
std::clog << "\t - Name: " << info << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_VENDOR, SZ_INFO, info, &sz)))
std::clog << "\t - Vendor: " << info << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_VERSION, SZ_INFO, info, &sz)))
std::clog << "\t - Version: " << info << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_TYPE, sizeof(dt), &dt, &sz)))
{
std::clog << "\t - Type: ";
switch (dt)
{
case CL_DEVICE_TYPE_CPU: std::clog << "CPU"; break;
case CL_DEVICE_TYPE_GPU: std::clog << "GPU"; break;
case CL_DEVICE_TYPE_ACCELERATOR: std::clog << "Accelerator"; break;
case CL_DEVICE_TYPE_DEFAULT: std::clog << "Default"; break;
default: std::clog << "ERROR";
}
std::clog << std::endl;
}
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_GLOBAL_MEM_SIZE, sizeof(memsz), &memsz, &sz)))
std::clog << "\t - Memory: " << (memsz / 1024 / 1024) << " MB" << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_MAX_CLOCK_FREQUENCY, sizeof(val), &val, &sz)))
std::clog << "\t - Max Frequency: " << val << " MHz" << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(val), &val, &sz)))
std::clog << "\t - Compute units: " << val << std::endl;
if (clCallSuccess(clGetDeviceInfo(devIDsAll[ii], CL_DEVICE_MAX_WORK_GROUP_SIZE, sizeof(mws), &mws, &sz)))
std::clog << "\t - Max workgroup size: " << mws << std::endl;
cl_context context = clCreateContext(NULL, 1, devIDsAll+ii, NULL, NULL, &err);
if (clCallSuccess(err) && context)
{
cl_command_queue command_queue = clCreateCommandQueueWithProperties(context, devIDsAll[ii], qProperties, &err);
if (clCallSuccess(err) && command_queue)
{
float perf = cl_BenchmarkDevice(context, command_queue, devIDsAll[ii]);
if ((perf > 0) && (perf < best_perf))
{
best_perf = perf;
best_device = devIDsAll[ii];
}
clCallSuccess(clReleaseCommandQueue(command_queue));
}
clCallSuccess(clReleaseContext(context));
}
}
}
}
}
return best_device;
}
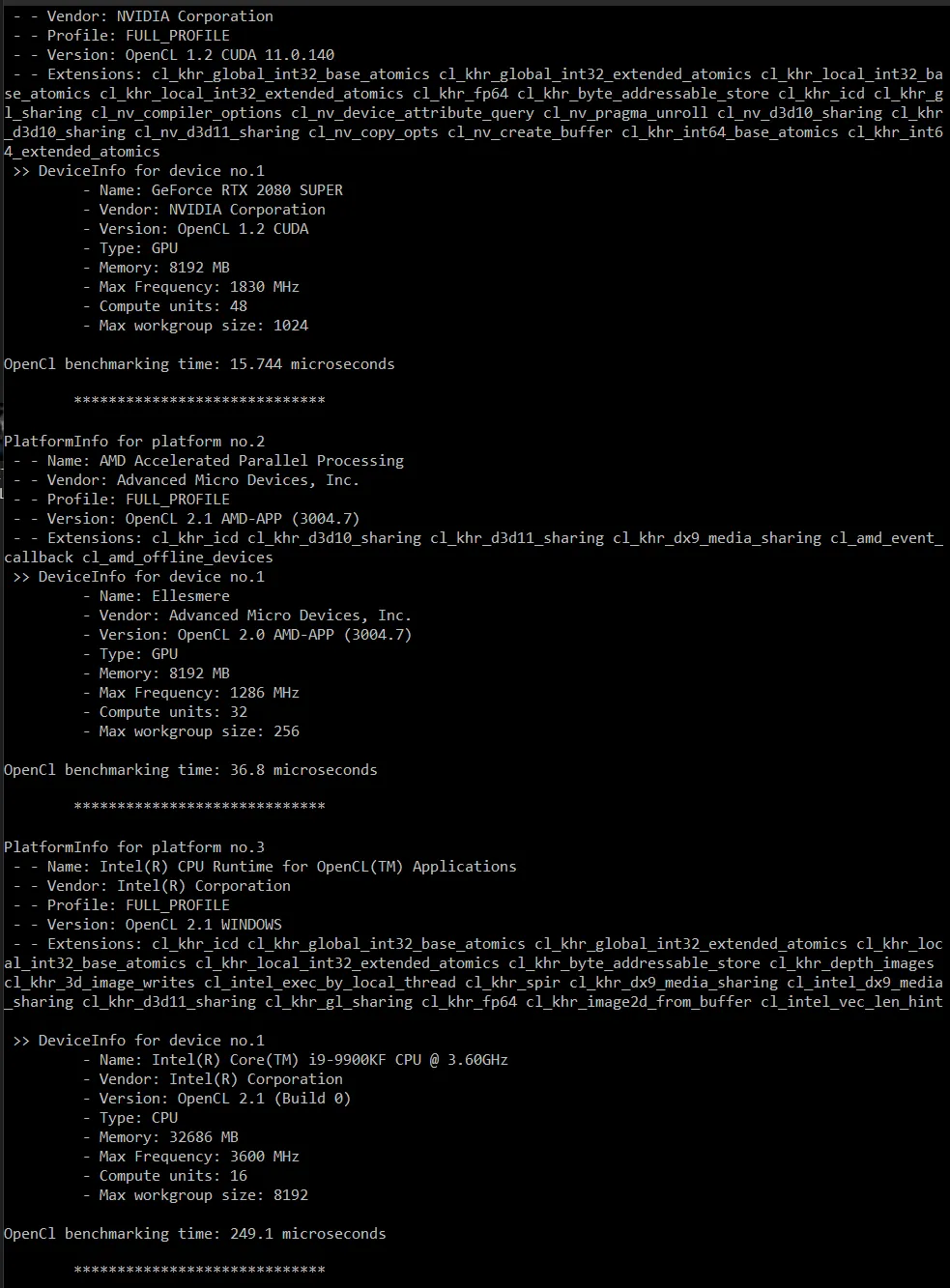
这里是我电脑上的输出结果
{kind=link}