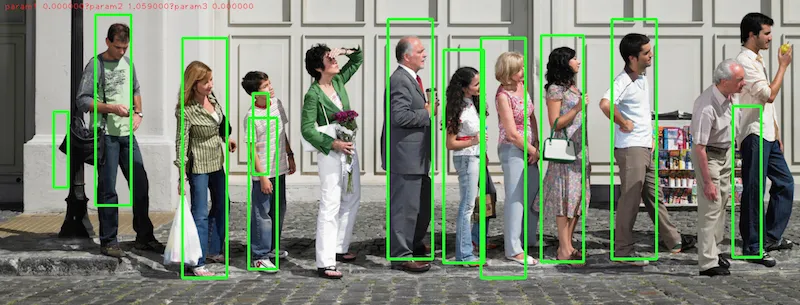
我在openCV上尝试了一个有关人员检测的示例。在对一张图片(可在这里找到原始图片)运行后,得出了以下结果:

我使用的是openCV捆绑的人员检测示例(稍作修改以避免Visual Studio错误)。以下是执行的代码:
// opencv-sample.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <stdio.h>
#include <string.h>
#include <ctype.h>
using namespace cv;
using namespace std;
// static void help()
// {
// printf(
// "\nDemonstrate the use of the HoG descriptor using\n"
// " HOGDescriptor::hog.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());\n"
// "Usage:\n"
// "./peopledetect (<image_filename> | <image_list>.txt)\n\n");
// }
int main(int argc, char** argv)
{
Mat img;
FILE* f = 0;
char _filename[1024];
if (argc == 1)
{
printf("Usage: peopledetect (<image_filename> | <image_list>.txt)\n");
return 0;
}
img = imread(argv[1]);
if (img.data)
{
strcpy_s(_filename, argv[1]);
}
else
{
fopen_s(&f, argv[1], "rt");
if (!f)
{
fprintf(stderr, "ERROR: the specified file could not be loaded\n");
return -1;
}
}
HOGDescriptor hog;
hog.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());
namedWindow("people detector", 1);
for (;;)
{
char* filename = _filename;
if (f)
{
if (!fgets(filename, (int)sizeof(_filename) - 2, f))
break;
//while(*filename && isspace(*filename))
// ++filename;
if (filename[0] == '#')
continue;
int l = (int)strlen(filename);
while (l > 0 && isspace(filename[l - 1]))
--l;
filename[l] = '\0';
img = imread(filename);
}
printf("%s:\n", filename);
if (!img.data)
continue;
fflush(stdout);
vector<Rect> found, found_filtered;
double t = (double)getTickCount();
// run the detector with default parameters. to get a higher hit-rate
// (and more false alarms, respectively), decrease the hitThreshold and
// groupThreshold (set groupThreshold to 0 to turn off the grouping completely).
hog.detectMultiScale(img, found, 0, Size(8, 8), Size(32, 32), 1.05, 2);
t = (double)getTickCount() - t;
printf("tdetection time = %gms\n", t*1000. / cv::getTickFrequency());
size_t i, j;
for (i = 0; i < found.size(); i++)
{
Rect r = found[i];
for (j = 0; j < found.size(); j++)
if (j != i && (r & found[j]) == r)
break;
if (j == found.size())
found_filtered.push_back(r);
}
for (i = 0; i < found_filtered.size(); i++)
{
Rect r = found_filtered[i];
// the HOG detector returns slightly larger rectangles than the real objects.
// so we slightly shrink the rectangles to get a nicer output.
r.x += cvRound(r.width*0.1);
r.width = cvRound(r.width*0.8);
r.y += cvRound(r.height*0.07);
r.height = cvRound(r.height*0.8);
rectangle(img, r.tl(), r.br(), cv::Scalar(0, 255, 0), 3);
}
imshow("people detector", img);
imwrite("detected_ppl.jpg", img);
int c = waitKey(0) & 255;
if (c == 'q' || c == 'Q' || !f)
break;
}
if (f)
fclose(f);
return 0;
}
我希望能够提高这个结果的准确率,至少要检测出这张图片中的11个人中的9个。如何改进这个结果?我需要训练一个单独的SVM吗?还是有更好的库可以使用?或者我需要使用深度学习技术?
{kind=link}