我有一个非常大的3.5 GB CSV文件,我希望能够阅读它,根据各种输入条件进行排序和过滤以获取结果。我相信可以将其导入到MySQL数据库中并从那里开始处理,但是否有任何程序或在线工具可用于仅上传CSV文件,其余部分自动完成?
查看一个非常大的CSV文件?
9
- David michael
3
我曾经使用过几个在线服务来解析CSV文件,但是对于那么大的文件,很难说哪个会起作用。我怀疑任何免费的、粗制滥造的CSV解析器都不会让你上传一个3.5GB的文件。 :) 我猜把它放到某种数据库中可能是最好的选择。就我所知,像UltraEdit和Notepad++这样的工具可以处理非常大的文件,但不确定是否有帮助。 - trnelson
1你可能会从阅读以下内容中受益:
https://dev59.com/cnVC5IYBdhLWcg3w21Mq
这是关于文本文件的一般性问题,但你可能会得到一些好的建议。
尽管如此,我必须说,考虑到CSV文件的“数据库”特性,采用MySQL方式并不是一个坏主意。 - James
搜索“mysql批量加载csv”以获取其他选项。 - rheitzman
10个回答
8
- Estevão Lucas
5
由于它是一个CSV文件。
- 下载http://openrefine.org/download.html
- 这是一个开源软件。解压缩openrefine.zip文件夹。
- 运行openrefine-2.7-rc.1\openrefine.exe。
- 它是一个Web应用程序。因此在Chrome浏览器中打开http://127.0.0.1:3333/。
- 上传大型CSV文件。在我的情况下,文件大小为3.61 GB,并且成功地打开了文件。
{kind=link}
- Siddarth Kanted
3
您可以尝试使用PostgreSQL 9.1+及其file_fdw (文件外部数据包装器),它会将CSV文件伪装成表格。如果您用同名的另一个CSV文件替换原来的CSV文件,那么您将立即在数据库中看到新的信息。
您可以通过使用材料化视图 (PG 9.3+) 来提高性能,它基本上从CSV数据创建了一个真正的数据库表格。您可以使用pgAgent来按计划刷新材料化视图。
另一种选择是使用COPY语句:
/* the columns in this table are the same as the columns in your csv: */
create table if not exists my_csv (
some_field text, ...
);
/* COPY appends, so truncate the table if loading fresh data again: */
truncate table my_csv;
/*
you need to be a postgres superuser to use COPY
use psql \copy if you can't be superuser
put the csv file in /srv/vendor-name/
*/
copy
my_csv
from
'/srv/vendor-name/my.csv'
with (
format csv
);
- Neil McGuigan
2
我曾遇到一个拥有超过300万行的csv文件无法在OpenOffice Calc、Writer或Notepad++中打开的问题。后来,我使用了OpenOffice 4 Base作为一种简单的解决方案,它可以链接到csv文件。以下是具体步骤(可能因为我使用的是德语版OpenOffice,所以措辞可能不准确):
1. 准备:文件需要使用.csv扩展名,第一行应该有字段名称。将文件放在新目录中,以避免混淆。否则,所有文件都将被导入。 2. 文件 - 新建 - 数据库。助手会自动弹出。 3. 连接到现有数据库,格式为TEXT(你的文件需要使用.csv扩展名)。 4. 下一步,选择文件路径(而不是文件本身),选择csv文件类型,选择正确的字段分隔符。 5. 点击下一步和完成。 6. 为新创建的数据库选择一个名称。
如果一切顺利,你现在就可以看到新创建的表格的表格视图了。
你也可以使用gVim查看文件,就像在notepad中一样,例如添加第一列的描述行。
你可以在这个表上创建查询。由于该表没有索引,因此查询速度相当慢。由于OpenOffice不会使用沙漏,所以系统似乎已经崩溃了。
Base非常有限,感觉像早期测试版。在该数据库中创建新表格是不可能的(因此无法从文本文件中选择插入查询)。导出为csv也不可能。结果可以比较合理地复制和粘贴到Calc中,但可能需要花费一定时间。
1. 准备:文件需要使用.csv扩展名,第一行应该有字段名称。将文件放在新目录中,以避免混淆。否则,所有文件都将被导入。 2. 文件 - 新建 - 数据库。助手会自动弹出。 3. 连接到现有数据库,格式为TEXT(你的文件需要使用.csv扩展名)。 4. 下一步,选择文件路径(而不是文件本身),选择csv文件类型,选择正确的字段分隔符。 5. 点击下一步和完成。 6. 为新创建的数据库选择一个名称。
如果一切顺利,你现在就可以看到新创建的表格的表格视图了。
你也可以使用gVim查看文件,就像在notepad中一样,例如添加第一列的描述行。
你可以在这个表上创建查询。由于该表没有索引,因此查询速度相当慢。由于OpenOffice不会使用沙漏,所以系统似乎已经崩溃了。
Base非常有限,感觉像早期测试版。在该数据库中创建新表格是不可能的(因此无法从文本文件中选择插入查询)。导出为csv也不可能。结果可以比较合理地复制和粘贴到Calc中,但可能需要花费一定时间。
- Gunnar Bernstein
1
你可以使用内置的Excel连接来完成这个任务。
原始来源:https://excel.officetuts.net/en/examples/open-large-csv 步骤:
原始来源:https://excel.officetuts.net/en/examples/open-large-csv 步骤:
- 创建一个新的Excel文件
- 转到“数据”>> “获取和转换数据” >> “从文件” >> “从文本/CSV”并导入CSV文件。
- 过一会儿,您将看到一个带有文件预览的窗口。
- 点击负载按钮旁边的小三角。
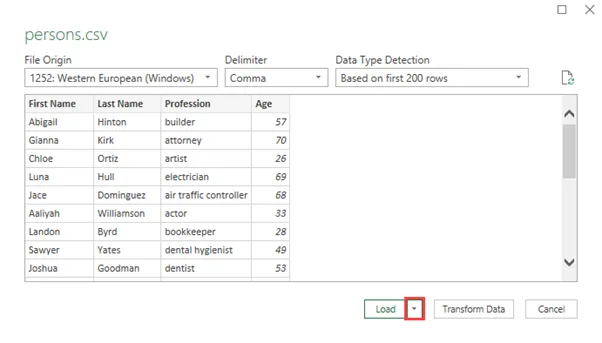
- 选择“加载到…”
- 现在,我们需要创建一个连接并将数据添加到数据模型中。这不会将数据加载到Excel表格中,因为那里有约一百万行的限制。
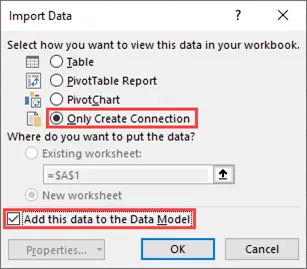
- 点击“确定”。这需要一段时间才能加载。
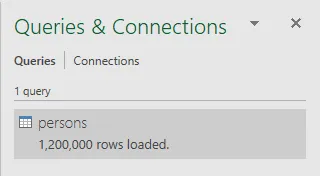
- 在右侧,您可以看到我们文件的名称和行数。如果保存文件,您会注意到其大小显着增加。
- 双击此区域以打开 Power Query 编辑器。
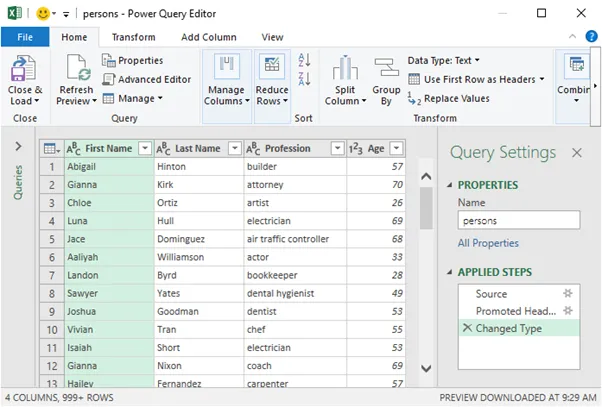
- 现在,如果您向下滚动,您会注意到新行是即时添加的。
- 要更改值,请右键单击单元格并选择“替换值”。

- 它将在“职业”列下将所有“建筑商”替换为“屋顶工人”。
- A W
0
我有一个包含大约1亿条记录的文件,我使用Linux命令行查看文件(只是浏览一下)。
$ more myBigFile.CSV
或者
$ nano myBigFile.CSV
它可以处理6 GB的文件。
- Mohammad Alqudah
0
如果它是一个平面的.CSV文件,并且不涉及数据管道,我对“其余部分自动化”的含义不太确定。
访问更大的.CSV文件的典型解决方案是:
- 将您的.CSV文件插入到SQL数据库中,如MySQL、PostgreSQL等。
您需要设计表模式,找到一个托管数据库的服务器,并编写服务器端代码来维护或更改数据库。
- 使用Python或R处理您的数据。
在GB级别的数据上运行Python和R会给您的本地计算机带来很多压力。这也更适合于数据探索和分析,而不是表操作。
- 为您的数据查找一个数据中心。例如,Acho Studio。
数据中心要容易得多,但它的成本可能会有所不同。它确实带有一个GUI,可以帮助您轻松地对表进行排序和筛选。
- Desmond830
0
你可以尝试使用Acho。它是一个在线工具,也提供免费试用。我推荐它是因为它的界面看起来非常好看和直观。此外,它拥有你提到的所有功能,包括排序或过滤值。基本上,我使用它来缩小数据集的大小并将其导出到Python进行进一步分析。
- Crystal L
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接