更新
在评论中发现我采用的基准测试方法是错误的,因此结果是误导性的。在更正我的方法后(如接受的答案所示),结果与预期相同——JDK 13的性能与JDK 11一样好。有关详细信息,请参见答案。
原始问题
我正在对 Windows 10 下的 HashSet 进行一些性能基准测试,使用以下 JMH 测试代码:
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1, warmups = 1)
public void init() {
HashSet<String> s = new HashSet<>();
for (int i = 0; i < 1000000; i++) {
s.add(Math.random() + "");
}
s.size();
}
我在不同的JDK版本下编译并运行了它,以下是我的测试结果:
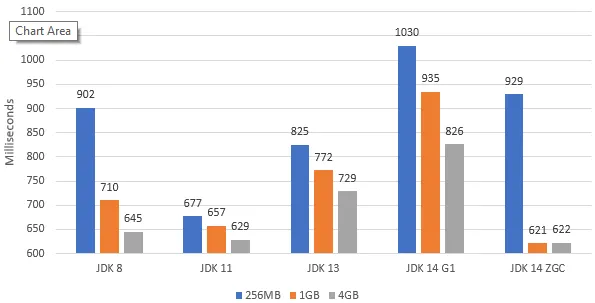
我还尝试了不同的堆大小(因此每个JDK有3种不同的颜色)。 当然,JDK 14只是今天的预发布快照-只是为了看看ZGC在Windows下的表现。
我想知道,在JDK 11之后发生了什么?(请注意,对于JDK 12,即使它不在上图中,它也已经开始增长)
Integer.toString(i)而不是Math.random() + "",结果是否相似?我很好奇回归是由于生成随机数还是HashSet本身。 - Jacob G.init方法没有返回值?而且你也没有Blackhole::consume方法?如果你把这个warmups也删除了会发生什么呢?在我看来,如果你只使用C2编译器运行这段代码,所有值都应该接近于零,因为这个方法可以被视为 NOOP(无操作)。 - EugeneMath.random()会推进全局可见的Random种子的状态。基本上,这段代码是在测试Math.random()的效率... - Holger-prof gcJMH选项或切换到Parallel GC来看到这一点,后者在两个JDK版本中表现几乎相同。请注意,您的基准测试不测量HashSet的性能。根据async-profiler的数据,约50%的CPU时间用于GC,~25%用于将double转换为String。 - apangin