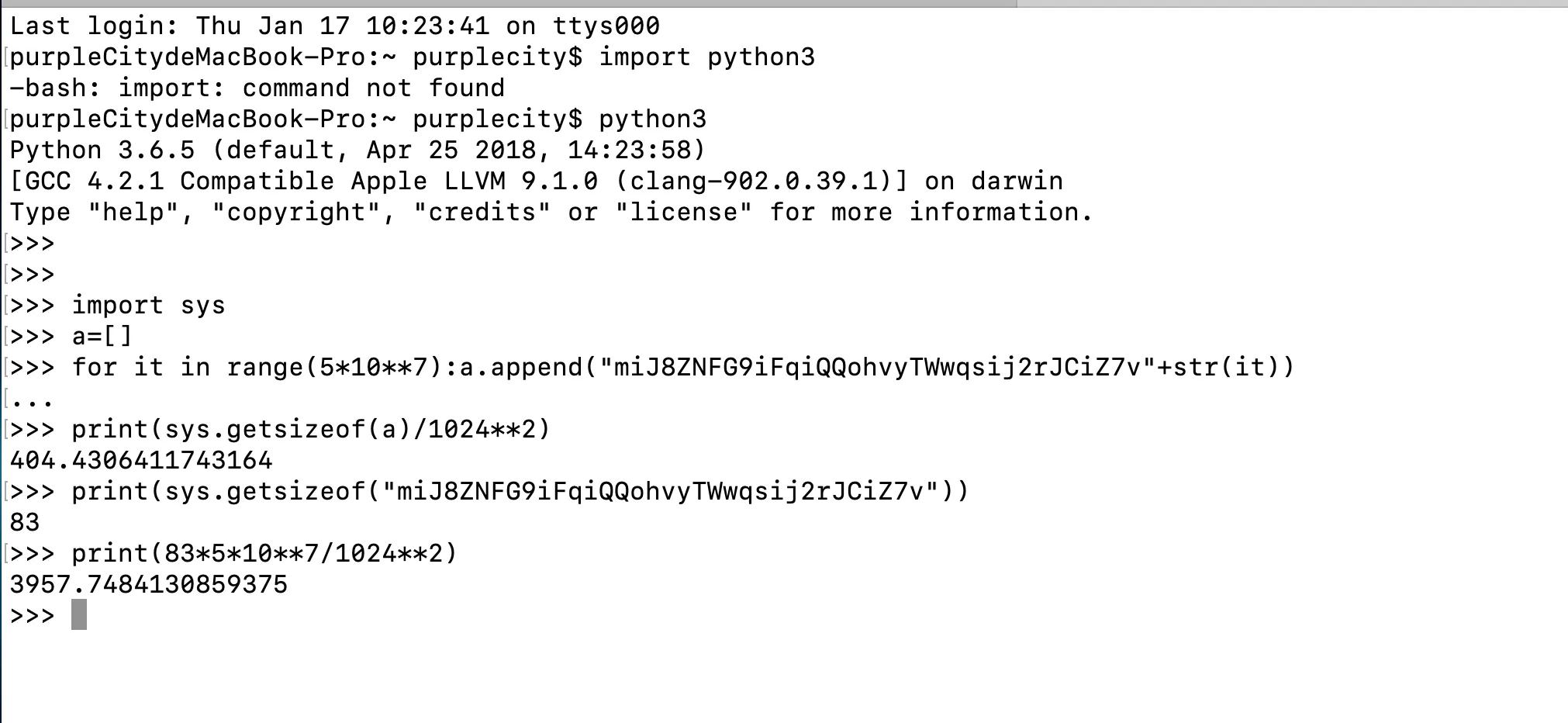
如图所示,5000万条记录只需要404M内存,这是为什么呢?因为每个记录占用83个字节,5000万条记录应该需要3967M内存。
我们可以使用数据压缩技术将数据存储在更少的内存中。这样不仅可以减小存储开销,而且可以提高数据处理效率。在实际应用中,我们可以根据具体情况选择不同的压缩算法和压缩级别。
>>> import sys
>>> a=[]
>>> for it in range(5*10**7):a.append("miJ8ZNFG9iFqiQQohvyTWwqsij2rJCiZ7v"+str(it))
...
>>> print(sys.getsizeof(a)/1024**2)
404.4306411743164
>>> print(sys.getsizeof("miJ8ZNFG9iFqiQQohvyTWwqsij2rJCiZ7v"))
83
>>> print(83*5*10**7/1024**2)
3957.7484130859375
>>>