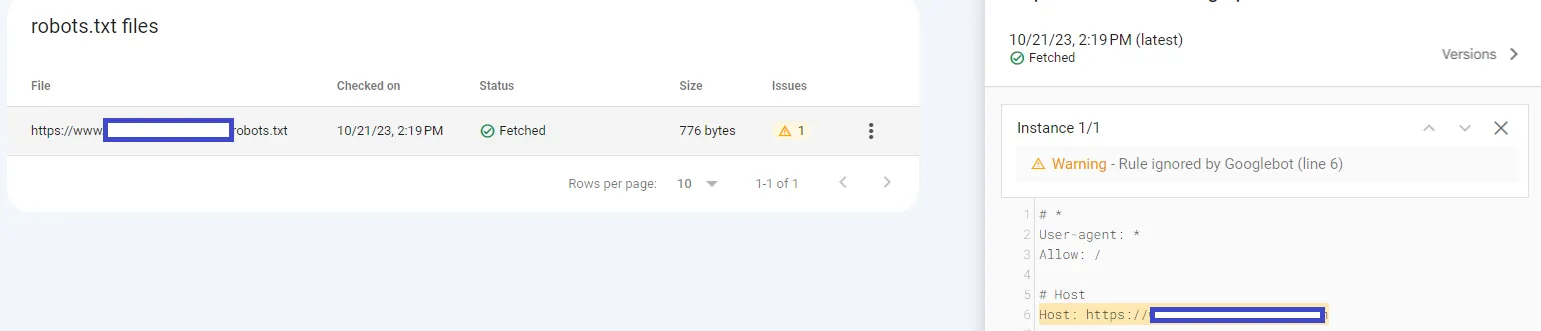
在寻找关于robots.txt的特定信息时,我偶然发现了一个有关此主题的Yandex帮助页面‡。它建议我可以使用Host指令来告诉网络爬虫我的首选镜像域:
User-Agent: *
Disallow: /dir/
Host: www.example.com
同时,维基百科条目指出Google也理解Host指令,但没有太多(即零)信息。
在robotstxt.org上,我没有找到关于Host(或维基百科上提到的Crawl-delay)的任何内容。
- 是否鼓励使用
Host指令? - Google是否有关于这个
robots.txt的专门资源? - 其他网络爬虫的兼容性如何?
‡ 至少自2021年初以来,链接的条目不再涉及所讨论的指令。