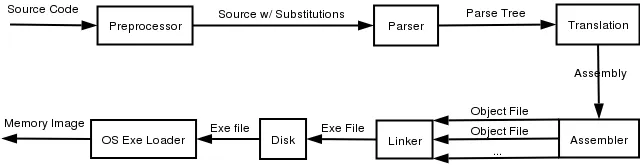
.o文件是目标文件,它是最终程序的中间表示形式。通常情况下,.o文件包含编译后的代码,但它没有所有不同例程或数据的最终地址。在程序运行之前,需要的一个东西类似于内存映像。例如,如果您有一个主程序并调用一个例程A(这是虚假的Fortran语言,在几十年前就已经过时了,请跟我一起工作)。
PROGRAM MAIN
INTEGER X,Y
X = 10
Y = SQUARE(X)
WRITE(*,*) Y
END
然后你有平方函数。
FUNCTION SQUARE(N)
SQUARE = N * N
END
它们是单独编译的单元。当编译MAIN时,它不知道“SQUARE”在哪里,也不知道它的地址。所以当它调用微处理器的JUMP SUBROUTINE(JSR)指令时,指令需要有一个地方可以跳转。
.o文件已经包含了JSR指令,但它没有实际值。这个值在链接或加载阶段(取决于应用程序)后才会出现。
因此,MAINS .o文件具有主函数的所有代码和一系列需要解决的引用(特别是SQUARE)。SQUARE基本上是独立的,没有任何引用,但同时,它也没有存在于内存中的地址。
连接器将把所有的.o文件合并成一个可执行文件。在旧日子里,编译后的代码实际上是一个内存映像。程序将从某个地址开始,直接全部加载到RAM中,然后执行。因此,在这种情况下,你可以看到连接器将两个.o文件连接在一起(以获取SQUARE的实际地址),然后返回到MAIN中查找SQUARE引用,并填写地址。
现代连接器不会走得那么远,而是将大部分最终处理推迟到实际加载程序时进行。但概念是相似的。
通过编译为.o文件,您最终获得了可重用的逻辑单元,这些单元稍后会在链接和加载过程中组合在一起以进行执行。
另一个好处是.o文件可以来自不同的语言。只要调用机制兼容(即如何传递参数到函数和过程),那么一旦编译成.o,源语言就变得不那么重要了。您可以将C代码与FORTRAN代码链接和组合在一起。
在PHP等语言中,过程略有不同,因为所有代码都在运行时加载到单个映像中。您可以将FORTRAN的.o文件视为如何使用PHP的include机制将文件组合成一个大而完整的整体。