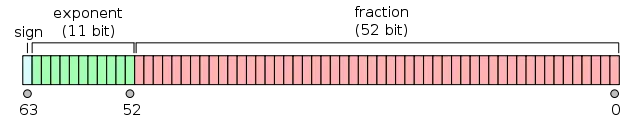
编辑:所以基本上我想编写的是一个针对double的1位哈希。
我想将double映射为true或false,并且有50/50的机会。为此,我编写了代码,选择一些随机数(仅作为示例,我想在具有规律性的数据上使用此代码,仍然获得50/50的结果),检查它们的最后一位,并在1时增加y,或者在0时增加n。
然而,这段代码经常导致25%的y和75%的n结果。为什么不是50/50呢?为什么会出现这样奇怪但直接的(1/3)分布?
public class DoubleToBoolean {
@Test
public void test() {
int y = 0;
int n = 0;
Random r = new Random();
for (int i = 0; i < 1000000; i++) {
double randomValue = r.nextDouble();
long lastBit = Double.doubleToLongBits(randomValue) & 1;
if (lastBit == 1) {
y++;
} else {
n++;
}
}
System.out.println(y + " " + n);
}
}
示例输出:
250167 749833
{kind=link}
doubleValue % 1 > 0.5,但这会过于粗糙,因为它可能会在某些情况下引入可见的规律性(所有值都在长度为1的范围内)。如果这太粗糙了,那么我们应该尝试更小的范围,比如doubleValue % 1e-10 > 0.5e-10?好的,是的。当你一直遵循这种方法到最后,使用最小的模数,只取double的最后一位作为哈希值。 - gvlasov(lastbit & 3) == 0可以起作用。 - harold