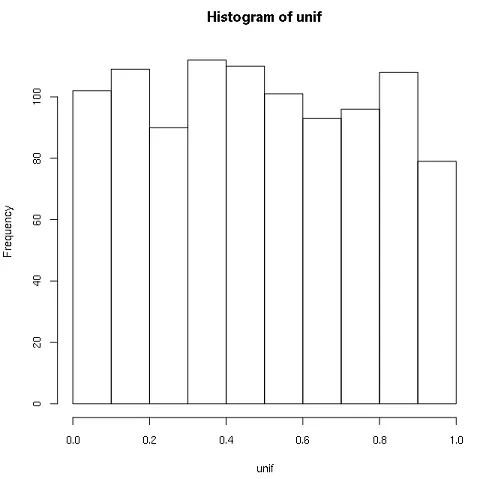
使用倒置输入分布加权的示例
啊哈!我想到了第二种解决方案,我认为这可能比我的第一种方案更好,我将其保存在下面的重复目标分配最近匹配选择部分中。
sample()函数有一个prob参数,允许我们为输入向量的元素指定概率权重。我们可以使用这个参数来增加选择出现在输入分布的稀疏段(即尾部)中的元素的概率,并减少选择出现在密集段(即中心)中的元素的概率。我认为简单地倒置密度函数dnorm()就足够了:
测试数据
set.seed(1L);
normSize <- 1e4L; normMean <- 0.5; normSD <- 0.25;
norm <- rnorm(normSize,normMean,normSD);
解决方案
unifSize <- 1e3L; unifMin <- 0; unifMax <- 1;
normForUnif <- norm[norm>=unifMin & norm<=unifMax];
d <- dnorm(normForUnif,normMean,normSD);
unif <- sample(normForUnif,unifSize,prob=1/d);
hist(unif);
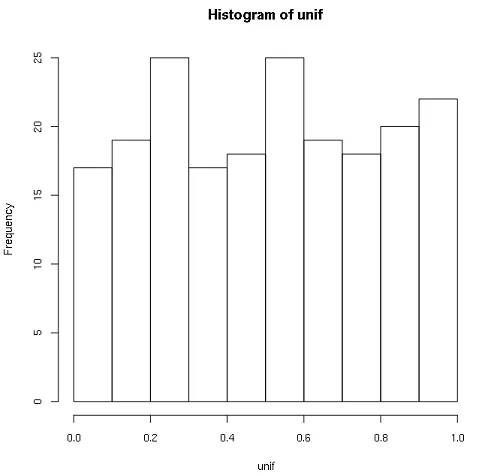
反复目标分布最近匹配选择
从目标(均匀)分布生成一组随机偏差。对于每个偏差,找到与之最接近的输入(正常)分布元素。将该元素视为选择样本。
重复上述步骤,直到唯一选择的数量达到或超过样本所需大小。如果超过了所需大小,则将其截断至所需大小。
我们可以使用findInterval()来查找每个均匀偏差的最接近正常偏差。这需要一些调和才能做好。我们必须对正常分布向量进行排序,因为findInterval()需要排序后的vec。而且,我们必须通过不低于零的最低值来传递给runif(),而不是使用目标分布的真实最小值,否则,低于该值的均匀偏差将匹配低于均匀分布可接受最小值的输入元素。此外,在运行调用findInterval()的循环之前,为了效率,最好从正常分布向量中删除所有不在目标分布可接受范围内(即[0,1])的值,这样它们将不参与匹配算法。它们是不需要的,因为它们无论如何都无法匹配。
如果目标样本大小比输入分布向量小足够多,则应该消除结果样本中任何输入分布的痕迹。
测试数据
set.seed(1L);
normSize <- 1e6L; normMean <- 0.5; normSD <- 0.25;
norm <- rnorm(normSize,normMean,normSD);
解决方案
unifSize <- 200L; unifMin <- 0; unifMax <- 1;
normVec <- sort(norm[norm>=unifMin & norm<=unifMax]);
inds <- integer();
repeat {
inds <- unique(c(inds,findInterval(runif(unifSize*2L,normVec[1L],unifMax),normVec)));
if (length(inds)>=unifSize) break;
};
length(inds) <- unifSize;
unif <- normVec[inds];
hist(unif);
需要注意的是,findInterval() 函数并不会准确地找到最接近的元素,而是找到小于或等于搜索值的元素。我认为这不会对结果产生任何重大影响;最多,它会微不足道地偏向于较小的值,但是以一种均匀的方式。如果您真的想要,可以查看各种查找最接近选项,例如请参见R: find nearest index。